Relationale Datenbanken
Relationale Datenbanken
Datenbanksysteme erlauben Abfrage, Manipulation und Verwaltung gespeicherter Daten. Sie haben zum Ziel, Daten dauerhaft, effizient und konsistent zu speichern.
Datenmodelle bestimmen, in welcher Form Daten in der Datenbank angelegt werden. Am häufigsten wird das sogenannte relationale Datenmodell verwendet. Dabei werden Daten in Tabellen abgelegt.
Jede Zeile einer Tabelle entspricht einem Datensatz. Die Spalten einer Tabelle werden auch Attribut genannt und Datensätze bestehen dementsprechend aus Attributwerten.
Als Beispiel betrachten wir die folgende Tabelle mit den Attributen DozentNachname, DozentVorname und VorlesungsTitel.
Table: Vorlesungsverzeichnis
| DozentNachname | DozentVorname | VorlesungsTitel |
|---|---|---|
| Huch | Frank | Informatik für Nebenfächler |
| Fischer | Sebastian | Weiterbildung Informatik |
| Huch | Frank | Weiterbildung Informatik |
Die Tabelle enthält (den Zeilen entsprechend) drei Datensätze mit (den Spalten entsprechend) jeweils drei Attributwerten. Die Attributwerte des ersten Datensatzes sind zum Beispiel die Zeichenketten “Huch”, “Frank” und “Informatik für Nebenfächler”.
Während die Reihenfolge der Attribute (also Spalten) relevant ist, spielt die Reihenfolge der Datensätze (also Zeilen) im relationalen Datenmodell keine Rolle. (Deshalb ist es fragwürdig, wie eben vom “ersten Datensatz” zu sprechen.) Auch Mehrfachvorkommen von Zeilen werden ignoriert. Eine Tabelle wird also nicht als Liste sondern als Menge von Datensätzen interpretiert. Da Datensätze mathematisch als Tupel dargestellt werden können, entspricht eine Tabelle einer Menge von Tupeln, also einer Relation. So erklärt sich der Name relationales Datenmodell.
Schlüssel zum Referenzieren von Datensätzen
Relationale Datenbanken können mehrere Tabellen verwalten, die aufeinander verweisen. Um auf Datensätze einer Tabelle verweisen zu können, müssen diese eindeutig referenzierbar sein. Dies geschieht mit Hilfe sogenannter Schlüssel.
Als Beispiel betrachten wir die beiden folgenden Tabellen, die die selben Daten darstellen wie das obige Vorlesungsverzeichnis.
Table: Vorlesungen
| DozentNachname | VorlesungsTitel |
|---|---|
| Huch | Informatik für Nebenfächler |
| Fischer | Weiterbildung Informatik |
| Huch | Weiterbildung Informatik |
Table: Dozenten
| DozentNachname | DozentVorname |
|---|---|
| Huch | Frank |
| Fischer | Sebastian |
Bei dieser Darstellung werden die Vorlesungstitel in der Tabelle Vorlesungen nur noch zusammen mit den Nachnamen der Dozenten gespeichert. Die zu den Nachnamen gehörenden Vornamen sind in Tabelle Dozenten den Nachnamen zugeordnet. Diese Darstellung setzt vorraus, dass es keine zwei Dozenten mit dem selben Nachnamen gibt. Ansonsten wäre die Zuordnung der Dozenten zu einer Vorlesung nicht eindeutig. Wir gehen zunächst vereinfachend von solcher Eindeutigkeit aus. Das Attribut DozentNachname legt dann die Datensätze in der Tabelle Dozenten eindeutig fest und wird deshalb Schlüssel der Tabelle genannt.
Im Allgemeinen bezeichnet man als Schlüssel eine Menge von Attributen, deren Attributwerte die Datensätze einer Tabelle eindeutig festlegen. (Der eben diskutierte Schlüssel ist also eigentlich die einelementige Menge, die nur aus dem Attribut DozentNachname besteht.) Eine Tabelle kann mehrere Schlüssel haben. Die Menge aller Attribute einer Tabelle ist immer ein Schlüssel, da Datensätze gemäß des relationalen Datenmodells nicht doppelt vorkommen.
Zum Beispiel ist die Menge {DozentVorname} ebenfalls ein Schlüssel für die Tabelle Dozenten, wenn wir vorraussetzen, dass es keine zwei Dozenten mit dem selben Vornamen gibt.
Die Tabelle Vorlesungen hat keine einelementigen Schlüssel, da es zu jedem Dozent mehrere Vorlesungen geben kann und umgekehrt. Der einzige Schlüssel der Tabelle Vorlesungen ist also die Menge aller Attribute {DozentNachname,Vorlesungstitel}. Schlüssel aus mehreren Attributen werden Verbundschlüssel genannt.
Benutzer einer relationalen Datenbank müssen zu jeder Tabelle einen Schlüssel angeben, der zur Referenzierung ihrer Datensätze verwendet wird. Dieser so ausgezeichnete Schlüssel einer Tabelle wird Primärschlüssel genannt. Weitere Schlüssel können als sogenannte Sekundärschlüssel deklariert werden, was hilfreich sein kann, um Suchanfragen zu beschleunigen.
Die Tabelle Vorlesungen hat nur einen Schlüssel, der also auch der Primärschlüssel ist. Für die Tabelle Dozenten haben wir als Primärschlüssel {DozentNachname} gewählt und verwenden entsprechende Attributwerte zur Referenzierung von Dozenten aus der Tabelle Vorlesungen. Die Attributmenge {DozentNachname} wird deshalb Fremdschlüssel in der Tabelle Vorlesungen genannt. (Sie ist kein Schlüssel dieser Tabelle!)
Im Allgemeinen müssen Primär- und Fremdschlüssel nicht identisch sein. Es genügt, wenn die zugehörigen Typen der Attribute kompatibel sind.
Die Darstellung mit zwei Tabellen hat gegenüber der ursprünglichen Darstellung als eine einzige Tabelle Vorlesungsverzeichnis den Vorteil, dass Vornamen von Dozenten nicht mehr redundant gespeichert werden. Um einen Vornamen eines Dozenten zu ändern, braucht nur noch ein einziger Datensatz in der Tabelle Dozenten geändert zu werden statt aller zugehörigen Datensätze in der Tabelle Vorlesungsverzeichnis. Dadurch wird auch vermieden, dass der selbe Dozent versehentlich mit verschiedenen Vornamen gespeichert wird.
Unsere Annahme, dass Dozenten eindeutig über ihren Nachnamen (oder Vornamen) identifiziert werden können ist unrealistisch. Statt wie in der Tabelle Vorlesungen die Menge aller Attributwerte als Primärschlüssel zu verwenden, können wir der Tabelle ein weiteres Attribut hinzufügen, welches die Datensätze eindeutig beschreibt (also eine ID darstellt). Relationale Datenbanksysteme unterstützen die Definition solcher Attribute mit einer fortlaufenden Nummer als Attributwert. Durch die fortlaufende Nummerierung sind solche Attribute automatisch Schlüssel und werden Surrogatschlüssel genannt.
Um Dozenten mit gleichen Vor- oder Nachnamen nicht von vornherein auszuschließen, ändern wir die Tabelle Dozenten wie folgt.
Table: Dozenten
| DozentID | DozentNachname | DozentVorname |
|---|---|---|
| 0 | Huch | Frank |
| 1 | Fischer | Sebastian |
Auch ohne die Eindeutigkeit von Vor- oder Nachnamen vorausszusetzen ist nun {DozentID} ein Schlüssel der Tabelle Dozenten. Wenn wir ihn als Primärschlüssel festlegen, können wir statt {DozentNachname} nun {DozentID} als Fremdschlüssel in der Tabelle Vorlesungen verwenden.
Table: Vorlesungen
| DozentID | VorlesungsTitel |
|---|---|
| 0 | Informatik für Nebenfächler |
| 1 | Weiterbildung Informatik |
| 0 | Weiterbildung Informatik |
Diese Darstellung eines Vorlesungsverzeichnis enthält noch immer Redundanz, da die Vorlesungstitel mehrfach gespeichert werden. Um auch diese Redundanz zu eliminieren, zerlegen wir die Tabelle Vorlesungen wie folgt in zwei Tabellen.
Table: IstDozent
| DozentID | VorlesungsID |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 0 | 1 |
Table: Vorlesungen
| VorlesungsID | VorlesungsTitel |
|---|---|
| 0 | Informatik für Nebenfächler |
| 1 | Weiterbildung Informatik |
Zur Verknüpfung der Dozenten mit Vorlesungen verwenden wir nun die Tabelle IstDozent. Diese referenziert die Tabellen Dozenten und Vorlesungen jeweils über Fremdschlüssel. Die Tabelle Vorlesungen identifiziert die Vorlesungstitel mit Hilfe des Surrogatschlüssels {VorlesungsID}, der auch ihr Primärschlüssel ist.
Die Tabelle IstDozent ist die einzige ohne einen einelementigen Schlüssel. Sie representiert eine sogenannte N-zu-M-Beziehung zwischen Dozenten und Vorlesungen. Neben N-zu-M-Beziehungen, die mit einer extra Tabelle dargestellt werden, gibt es auch 1-zu-1- und 1-zu-N-Beziehungen. Diese können einfacher (und ohne unnötige Redundanz) ohne extra Tabelle dargestellt werden. Hätte zum Beispiel jede Vorlesung nur einen Dozenten, so würde es genügen, ein zusätzliches Attribut DozentID als Fremdschlüssel in der Tabelle Vorlesungen zu verwenden. In diesem Fall wäre also die Version 20.5 der Tabelle Vorlesungen bereits redundanzfrei.
Ein Sonderfall ergibt sich bei 1-zu-1- und 1-zu-N-Beziehungen, wenn statt der 1 auch eine 0 zugelassen sein soll. Im bisherigen Entwurf der Tabelle Vorlesungen muss es zu jeder Vorlesung einen Dozenten geben. Ein Vorlesungstitel ohne Dozent lässt sich in die Tabelle nicht eintragen, ohne den Wert des Attributs DozentID leer zu lassen. Um dies zu erlauben, gibt es den sogenannten NULL-Wert, der als undefinierter Attributwert fungiert (Achtung: Ein NULL-Wert ist etwas anderes als der Zahlenwert 0 und wird von diesem unterschieden!).
Die drei Tabellen Dozenten, IstDozent und Vorlesungen representieren die selbe Information wie die ursprüngliche Tabelle Vorlesungsverzeichnis, wobei Redundanz in der ursprünglichen Darstellung eliminiert wurde. Die ursprüngliche Tabelle kann in gängigen relationalen Datenbanksystemen als sogenannte Sicht (“View”) extrahiert werden.
Daten-Integrität
Relationale Datenbanksysteme implementieren verschiedene Konsitenzprüfungen, die sicherstellen, dass die gespeicherten Daten sinnvoll interpretiert werden können.
Die einfachste Integritäts-Bedingung ist die sogenannte Bereichsintegrität. Diese fordert, dass Attributwerte zu einem dem Attribut zugeordneten Wertebereich (bzw. Typ) gehören. Zum Beispiel müssen im obigen Beispiel die Werte der Attribute DozentID und VorlesungsID Zahlen sein. Das Einfügen von Datensätzen mit ungültigen Attributwerten wird vom Datenbanksystem verhindert.
Die Forderung, dass der Primärschlüssel einer Tabelle die enthaltenen Datensätze eindeutig festlegt, wird als Entitätsintegrität bezeichnet. Das Einfügen von Datensätzen, deren zum Primärschlüssel gehörige Werte bereits in einem anderen Datensatz vorkommen, wird vom Datenbanksystem verhindert.
Aus der Referenzierung von Tabellen untereinander ergibt sich der Begriff der referentiellen Integrität. Diese fordert, dass zu den Werten eines Fremdschlüssels ein entsprechender Datensatz in der referenzierten Tabelle existiert. Gegebenenfalls ist auch NULL als Fremdschlüsselwert erlaubt (siehe oben). Verboten sind jedoch in jedem Fall Werte ungleich NULL zu denen kein Datensatz existiert. Ein Datenbanksystem verhindert das Einfügen eines Datensatzes, deren Fremdschlüssel keinen existierenden Datensatz referenziert.
Referentielle Integrität kann nicht nur durch Einfügen in der referenzierenden Tabelle sondern auch durch Löschen (oder Ändern) von Datensätzen in der referenzierten Tabelle verletzt werden. Um dies zu verhindern, gibt es verschiedene Strategien.
Die einfachste Strategie ist, das Löschen von referenzierten Datensätzen zu verbieten.
Falls NULL-Werte als Fremdschlüssel erlaubt sind, können Referenzen auf einen gelöschten Datensatz durch NULL überschrieben und dadurch gelöscht werden.
Eine dritte Strategie ist sogenannte Löschweitergabe, bei der referenzierende Datensätze zusammen mit dem referenzierten Datensatz gelöscht werden. Diese Vorgehensweise bietet sich insbesondere bei Tabellen an, die nur aus Fremdschlüsseln bestehen (wie IstDozent im obigen Beispiel), da dabei nur Referenzen gelöscht werden.
Neben den diskutierten Konsistenzbedingungen wird auch sogenannte logische Integrität betrachtet, die aber in der Regel nicht vom Datenbanksystem unterstützt wird. Zum Beispiel könnte man fordern, dass eine Vorlesung nur eine bestimmte Anzahl von Dozenten haben darf. Solche Bedingungen müssen von Anwendern eines Datenbanksystems selbst erfüllt werden.
ER-Diagramme
Die Struktur von Datenbanken wird in der Regel mit Hilfe sogenannter Entity-Relationship-Diagramme (kurz: ER-Diagramme) veranschaulicht. Dabei verhält sich im Kontext Relationaler Datenbanken eine Entität zu einem Datensatz wie eine Klasse zu einem Objekt im Kontext Objektorientierter Programmierung. Eine Entität beschreibt also den Typen zugehöriger Datensätze. Während in Klassen und Objekten jedoch Attribute und Methoden zusammengefasst sind, sind Entitäten und zugehörige Datensätze allein durch Attribute definiert. Entitäten beschreiben also Daten ohne zugehörige Operationen.
Die grafische Darstellung von Entitäten in ER-Diagrammen ähnelt der von Klassen in Klassendiagrammen. In einem Kasten, der mit dem Namen der Entität beschriftet ist, werden untereinander alle zugehörigen Attribute mit Namen und ggf. Typ aufgelistet. Zu jeder Entität gehört eine Tabelle in der Datenbank, die die zugehörigen Datensätze speichert.
Neben den Entitäten werden in ER-Diagrammen auch Beziehungen zwischen den Entitäten dokumentiert. Diese werden als Verbindung zwischen den Kästen gezeichnet. Die Beschriftung der Linien gibt an, wie die Beziehung heißt und ggf. auch, welche Fremdschlüssel an ihr beteiligt sind. Zusätzlich kennzeichnen sogenannte Kardinalitäten, um welche Art von Beziehung es sich handelt (1-zu-1, 1-zu-N oder N-zu-M). Auch N-zu-M-Beziehungen können in der Datenbank mit Hilfe von Tabellen dargestellt werden, die im Wesentlichen aus zwei Attributen für die Fremdschlüssel der beteiligten Entitäten bestehen.
Wie verwenden im Folgenden zur grafischen Darstellung eine etwas vereinfachte Version von ER-Diagrammen, in der Beziehungen zwischen Tabellen durch Verbindungslinien zwischen den Primär- und Fremdschlüsseln dargestellt werden, die je nach Kardinalität mit 1 oder N beschriftet sind. Die folgende Abbildung zeigt das Datenbankschema für die Vorlesungs-Datenbank (mit leicht geänderten Attributnamen, Primärschlüssel sind hier unterstrichen), die wir im Folgenden weiterverwenden werden:

Solche Diagramme lassen sich mit einfachen Zeichenprogrammen wie LibreDraw oder mit speziellen Diagramm-Editoren erstellen, z. B. mit dem Online-Editor diagrams.net (siehe auch Quellen und Lesetipps).
Datenbankanfragen mit SQL
SQL ist eine Sprache mit der Datenbanken verwaltet, durchsucht und manipuliert werden
können. Auf Datenbanken im SQLite-Format können wir mit dem
Kommandozeilenprogramm sqlite3 interaktiv zugreifen.1 Wie beginnen hier
mit einigen Beispielen für sogenannte select-Anfragen an eine Datenbank, in der das
beschriebene Vorlesungsverzeichnis abgelegt ist,
wobei Namen von Tabellen und Attributen teilweise abweichen.
Datensätze abfragen
Die erste Anweisung geben wir in ein Terminal ein, um sqlite3 zu starten und die
SQLite-Datenbank in der Datei Vorlesungen.db zu öffnen. Die folgenden Anweisungen
geben wir in die Kommandozeile des Programms sqlite3 ein, um Anfragen zu stellen:
$ sqlite3 Vorlesungen.db
sqlite> select 6*7;
42
sqlite> select Vorname, Nachname from Dozenten;
Frank|Huch
Sebastian|Fischer
sqlite> select * from Dozenten;
1|Frank|Huch
2|Sebastian|Fischer
sqlite> select * from Vorlesungen;
1|Informatik für Nebenfach
2|IQSH Weiterbildung Informatik
Eine select-Anfrage ist ein Ausdruck, dessen Wert eine Tabelle ist.
Im ersten Beispiel enthält diese Tabelle nur eine Spalte und eine Zeile,
wobei keine Daten aus Tabellen abgefragt werden, um das Ergebnis zu berechnen.
Solche Anfragen sind möglich, aber nicht sinnvoll – das Beispiel zeigt
aber, dass wir in SQL auch Berechnungen durchführen können.
Die beiden anschließenden Anfragen haben das gleiche Ergebnis:
Mit ihnen werden alle Datensätze der Tabelle Dozenten abgefragt und angezeigt.
Im ersten Beispiel fragen wir dabei nur die Attribute Vorname und Nachname
ab, im zweiten Beispiel fragen wir mit dem Platzhalter * alle Attribute ab
(was hier nur diese beiden sind). Die letzte Anfrage liefert die Datensätze
der Tabelle Vorlesungen.
SQL erlaubt jedoch mehr als den kompletten Inhalt von Tabellen abzufragen,
was besonders bei sehr großen Tabellen von Vorteil ist.
In einer select-Anfrage können mehrere Tabellen miteinander kombiniert
oder Ergebnisse mit Hilfe von Bedingungen eingeschränkt werden.
Die folgenden Anfragen demonstrieren, wie das geht.
sqlite> select * from Vorlesungen where Titel like 'IQSH%';
2|IQSH Weiterbildung Informatik
sqlite> select * from Dozenten, Vorlesungen;
1|Frank|Huch|1|Informatik für Nebenfach
1|Frank|Huch|2|IQSH Weiterbildung Informatik
2|Sebastian|Fischer|1|Informatik für Nebenfach
2|Sebastian|Fischer|2|IQSH Weiterbildung Informatik
sqlite> select * from Dozenten, Vorlesungen, IstDozent;
1|Frank|Huch|1|Informatik für Nebenfach|1|1
1|Frank|Huch|1|Informatik für Nebenfach|2|2
1|Frank|Huch|1|Informatik für Nebenfach|1|2
1|Frank|Huch|2|IQSH Weiterbildung Informatik|1|1
1|Frank|Huch|2|IQSH Weiterbildung Informatik|2|2
1|Frank|Huch|2|IQSH Weiterbildung Informatik|1|2
2|Sebastian|Fischer|1|Informatik für Nebenfach|1|1
2|Sebastian|Fischer|1|Informatik für Nebenfach|2|2
2|Sebastian|Fischer|1|Informatik für Nebenfach|1|2
2|Sebastian|Fischer|2|IQSH Weiterbildung Informatik|1|1
2|Sebastian|Fischer|2|IQSH Weiterbildung Informatik|2|2
2|Sebastian|Fischer|2|IQSH Weiterbildung Informatik|1|2
sqlite> select Vorname, Nachname, Titel
...> from Dozenten, Vorlesungen, IstDozent
...> where Dozenten.ID = IstDozent.DozentID and Vorlesungen.ID = IstDozent.VorlesungsID;
Frank|Huch|Informatik für Nebenfach
Sebastian|Fischer|IQSH Weiterbildung Informatik
Frank|Huch|IQSH Weiterbildung Informatik
In der ersten Anfrage werden alle Vorlesungen abgefragt, deren Titel mit IQSH
beginnt.
Das Prozentzeichen steht hierbei für beliebige weitere Zeichen.
Die anschließenden Anfragen zeigen, was passiert, wenn man mehrere Tabellen
in einer Anfrage kombiniert. Dabei wird jeder Datensatz der ersten Tabelle
mit jedem der zweiten (und so weiter) kombiniert.
Um das korrekte Vorlesungsverzeichnis abzufragen, filtern wir aus all diesen
Kombinationen solche heraus, bei denen die Werte des Attributs ID für
Datensätze der Tabellen Dozenten und Vorlesungen eine in der Tabelle
IstDozent gespeicherte Kombination bilden.
Views erzeugen
Die letzte Anfrage können wir mit der folgenden SQL-Anweisung in einem sogenannten View speichern. Anschließend können wir den erzeugten View wie eine Tabelle verwenden.
sqlite> create view Vorlesungsverzeichnis as
...> select Vorname, Nachname, Titel
...> from Dozenten, Vorlesungen, IstDozent
...> where Dozenten.ID = IstDozent.DozentID and Vorlesungen.ID = IstDozent.VorlesungsID;
sqlite> select * from Vorlesungsverzeichnis;
Frank|Huch|Informatik für Nebenfach
Sebastian|Fischer|IQSH Weiterbildung Informatik
Frank|Huch|IQSH Weiterbildung Informatik
Zu einem View wird nicht der Inhalt sondern die ihn erzeugende Anfrage in der Datenbank gespeichert. Dies hat zur Folge, dass sich der Wert eines Views ändern kann, wenn sich der Inhalt von ihm abgefragter Tabellen ändert.
Datensätze gruppieren
Ein weiteres nützliches Sprachmittel für SQL-Anfragen erlaubt es, Datensätze zu gruppieren.
sqlite> select count(*) from Vorlesungen;
2
sqlite> select Titel, count(Nachname)
...> from Vorlesungsverzeichnis
...> group by Titel;
Informatik für Nebenfach|1
IQSH Weiterbildung Informatik|2
sqlite> select Titel, count(Nachname) as Anzahl
...> from Vorlesungsverzeichnis
...> group by Titel
...> order by Anzahl desc;
IQSH Weiterbildung Informatik|2
Informatik für Nebenfach|1
Hier berechnen wir zuerst die Anzahl aller Vorlesungen und dann die Anzahl
von Dozenten zu jeder Vorlesung im Vorlesungsverzeichnis.
In der letzten Anfrage verwenden wir den sogenannten Alias Anzahl als
Attributnamen, um das Ergebnis absteigend nach diesem Attribut zu sortieren.
Mit SQL können Daten nicht nur abgefragt sondern auch verwaltet und manipuliert
werden. Ein Beispiel dafür haben wir oben mit der Anweisung create view
bereits gesehen. Neue Tabellen wir können wir mit Hilfe von create table
Anweisungen anlegen. Die bisher verwendeten Tabellen wurden mit den folgenden
Anweisungen erzeugt.
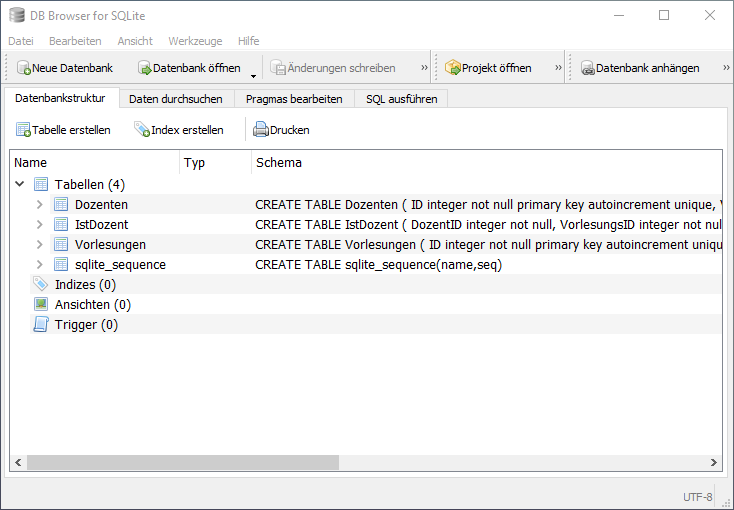
create table Dozenten (
ID integer not null primary key autoincrement unique,
Vorname text not null,
Nachname text not null
);
create table Vorlesungen (
ID integer not null primary key autoincrement unique,
Titel text not null
);
create table IstDozent (
DozentID integer not null,
VorlesungsID integer not null,
foreign key (DozentID) references Dozenten(ID) on delete cascade,
foreign key (VorlesungsID) references Vorlesungen(ID) on delete cascade
);
Die Anweisungen listen nach dem Namen der erzeugten Tabelle die Attributnamen
mit Eigenschaften der Attribute auf.
In der letzten Anweisung gibt nach den Definitionen der Attribute weitere Zeilen
für Fremdschlüsselbeziehungen, die den zugehörgen Primärschlüssel und
Löschweitergabe als Strategie zur Wahrung referentieller Integrität definieren.
Wird ein Dozent oder eine Vorlesung aus der Datenbank gelöscht, werden folglich
auch alle zugehörigen Datensätze aus der Tabelle IstDozent entfernt.
Daten manipulieren
Schließlich betrachten wir SQL-Anweisungen zur Manipulation von Daten.
Zum Löschen von Daten wird die delete-Anweisung verwendet, bei deren Verwendung
man dementsprechend vorsichtig sein sollte:
sqlite> delete from Dozenten;
sqlite> select * from Dozenten;
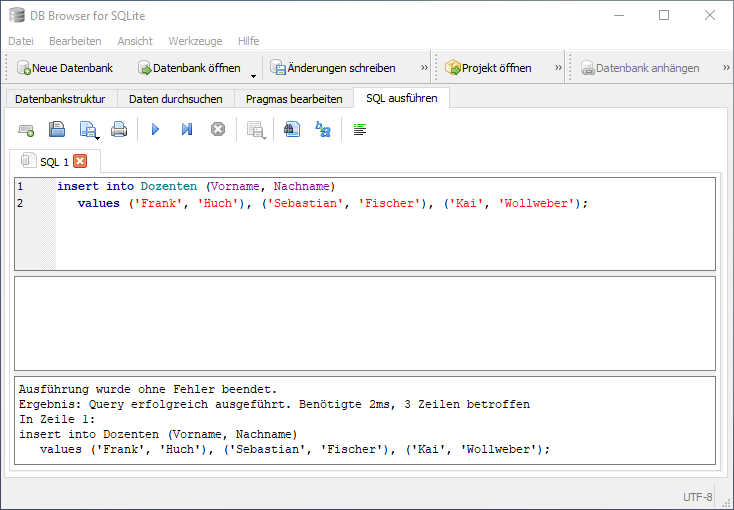
sqlite> insert into Dozenten(Vorname,Nachname)
...> values ('Frank','Huch'), ('Sebastian','Fischer'), ('Kai','Wollweber');
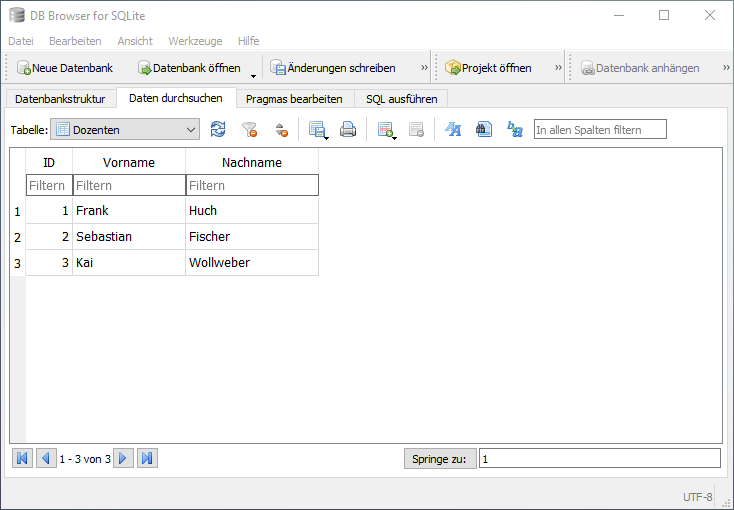
sqlite> select * from Dozenten;
8|Frank|Huch
9|Sebastian|Fischer
10|Kai|Wollweber
sqlite> delete from Dozenten where ID = 10;
sqlite> select * from Dozenten;
8|Frank|Huch
9|Sebastian|Fischer
Mit der ersten Anweisung wird der gesamte Inhalt der Tabelle Dozenten
(und bei aktivierter Löschweitergabe auch der Tabelle IstDozent)
gelöscht. Die anschließende insert-Anweisung fügt drei Datensätze in die
Dozenten-Tabelle ein, wobei kein Wert für das Attribut ID angegeben ist,
welches vom Datenbank-System automatisch gewählt wird.
Schließlich demonstriert eine weitere delete-Anweisung, wie man durch Angabe
einer Bedingung analog zu select-Anfragen Datensätze gezielt löschen kann.
Schließlich können wir mit Hilfe von update-Anweisungen existierende Datensätze manipulieren, wie das folgende Beispiel ziegt.
sqlite> select * from Vorlesungen;
1|Informatik für Nebenfach
2|IQSH Weiterbildung Informatik
sqlite> update Vorlesungen set Titel = 'IQSH Weiterbildung' where ID = 2;
sqlite> select * from Vorlesungen;
1|Informatik für Nebenfach
2|IQSH Weiterbildung
Tools
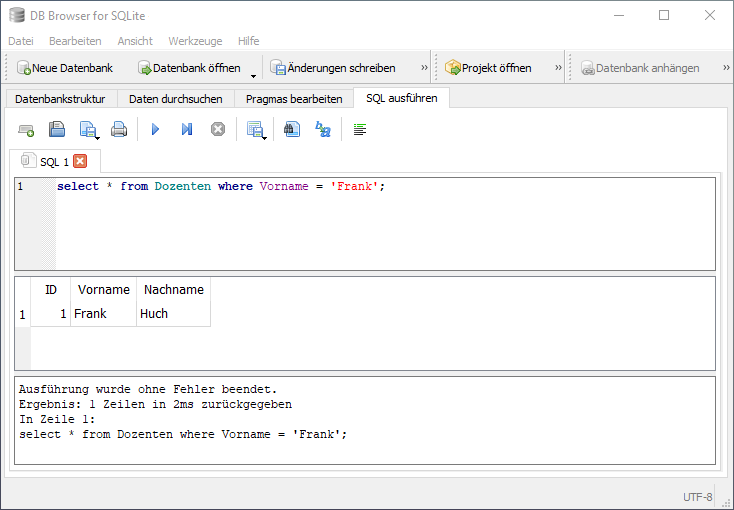
Statt der Kommandozeilenanwendung sqlite3 können auch Datenbank-Programme mit grafischer Benutzeroberfläche genutzt werden, um SQLite-Datenbanken zu erstellen, anzuzeigen und zu bearbeiten, sowie SQL-Anfragen auszutesten, was einen leichteren Zugang zur Thematik ermöglicht. Ein leichtgewichtiges, frei verfügbares Programm, das sich auch für den Schulunterricht eignet, ist der DB Browser für SQLite (Download-Link siehe Quellen und Lesetipps).
Quellen und Lesetipps
- SQL-Tutorial bei W3schools: https://www.w3schools.com/sql/
- Website zu SQLite: https://sqlite.org
- Hier finden Sie das Kommandozeilenprogramm
sqlite3unter Download (laden Sie das Archiv unter “A bundle of command-line tools” für Ihr Betriebssystem herunter), sowie eine Dokumentation zum Programm.
- Hier finden Sie das Kommandozeilenprogramm
- DB Browser for SQLite: https://sqlitebrowser.org
- Hier finden Sie ein grafisches Tool zum Anzeigen und Bearbeiten von SQLite-Datenbanken (als Alternative zum Kommandozeilenprogramm
sqlite3).
- Hier finden Sie ein grafisches Tool zum Anzeigen und Bearbeiten von SQLite-Datenbanken (als Alternative zum Kommandozeilenprogramm
- Online-Editor diagrams.net zum Erstellen von ER-Diagrammen: https://www.diagrams.net
Das Kommandozeilenprogramm
sqlite3kann von der SQLite-Homepage (siehe Quellen und Lesetipps heruntergeladen werden. ↩︎