Strukturierung mit HTML
Wie ist eine Webseite aufgebaut? Welche Arten von Elementen kann sie enthalten? Und wie lässt sich die Struktur von Webseiten beschreiben, so dass ein Browser sie interpretieren und uns präsentieren kann? Dazu wird eine speziell dafür entwickelte Sprache verwendet, nämlich HTML.
In dieser Lektion werden wir uns mit den grundlegenden Konzepten und Bestandteilen von HTML beschäftigen, die nötig sind, um einfache Webseiten mit einem Texteditor selbst zu erstellen und ihren Aufbau nachzuvollziehen. Ziel ist es nicht, einen vollständigen Überblick über HTML zu bekommen, sondern einen Einstiegspunkt zu finden und die grundlegende Idee zur Beschreibung strukturierter Hypertext-Dokumente anhand von HTML nachzuvollziehen. Zur Vertiefung eignen sich HTML-Referenzen und Tutorials wie W3Schools oder SELFHTML.
HTML
HTML steht kurz für Hypertext Markup Language (also “Auszeichnungssprache für Hypertext”) und stellt eine formale Sprache dar, mit der sich die Struktur von Webseiten in textueller Form beschreiben lässt. Dabei ist in erster Linie die semantische Struktur (Gliederung nach Bedeutung) gemeint, nicht die visuelle Struktur (grafische Präsentation) der Webseiten.
Im Rahmen der Weiterbildung wird ausschließlich die aktuelle HTML-Version HTML5 betrachtet, die langfristig ältere HTML-Standards als Kernsprache des World Wide Web ablöst. “HTML” wird im Folgenden also gleichbedeutend mit “HTML5” verwendet, wenn nicht anderes angegeben.
Webseiten werden in ihrer einfachsten Form wie Textdokumente gegliedert und formatiert, also mit Hilfe von Strukturelementen wie Überschriften, Absätzen, Listen und Tabellen. Weitere wichtige Elemente von Webseiten sind Hyperlinks (kurz “Links”), also speziell markierte Textteile, die Verweise zu anderen Webseiten darstellen, sowie eingebettete Bilder oder andere Multimedia-Elemente.
Eine HTML-Datei ist eine reine Textdatei, in der die Inhalte und die Struktur einer Webseite mit HTML beschrieben werden. Dazu werden Textabschnitte auf eine bestimmte Weise mit zusätzlicher Bedeutung versehen – sie werden also semantisch markiert oder “ausgezeichnet” (engl. to markup)1 – so dass ein Webbrowser sie interpretieren und geeignet darstellen kann.
Einstiegsbeispiel
Als anschauliches Beispiel wird hier eine sehr einfach aufgebaute Website betrachtet,2 die Sie unter der folgenden URL im Browser öffnen können:
https://weiterbildung-informatik.wollw.de/content/examples/bandpage/index.html
Die Website besteht aus mehreren Webseiten und Bildern, die wie folgt miteinander verknüpft sind (die Datei index.html dient hier als Einstiegsseite):
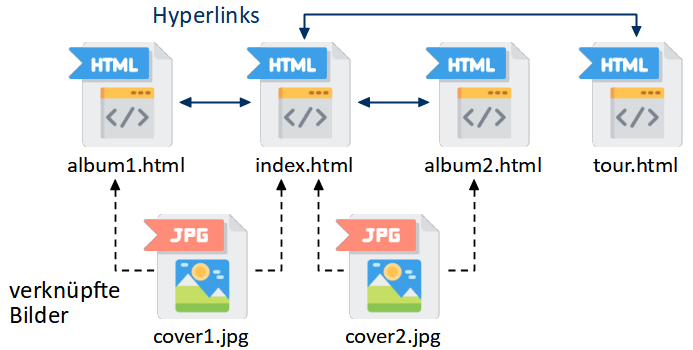
Sie können den HTML-Quelltext einer Webseite selbst im Browser untersuchen, indem Sie die Webseite öffnen, anschließend einen Rechtsklick auf die Seite ausführen und im Kontextmenü “Quelltext anzeigen” auswählen (je nach verwendetem Webbrowser heißt der Menüeintrag leicht unterschiedlich).
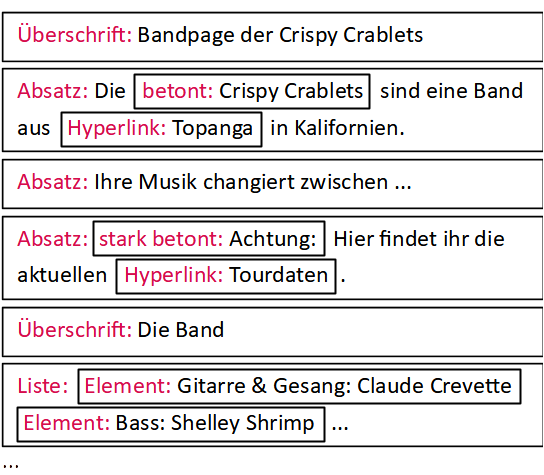
Die folgende Abbildung zeigt rechts den HTML-Quelltext der Webseite und links zum Vergleich die Präsentation der Webseite im Browser (zum Vergrößern anklicken):
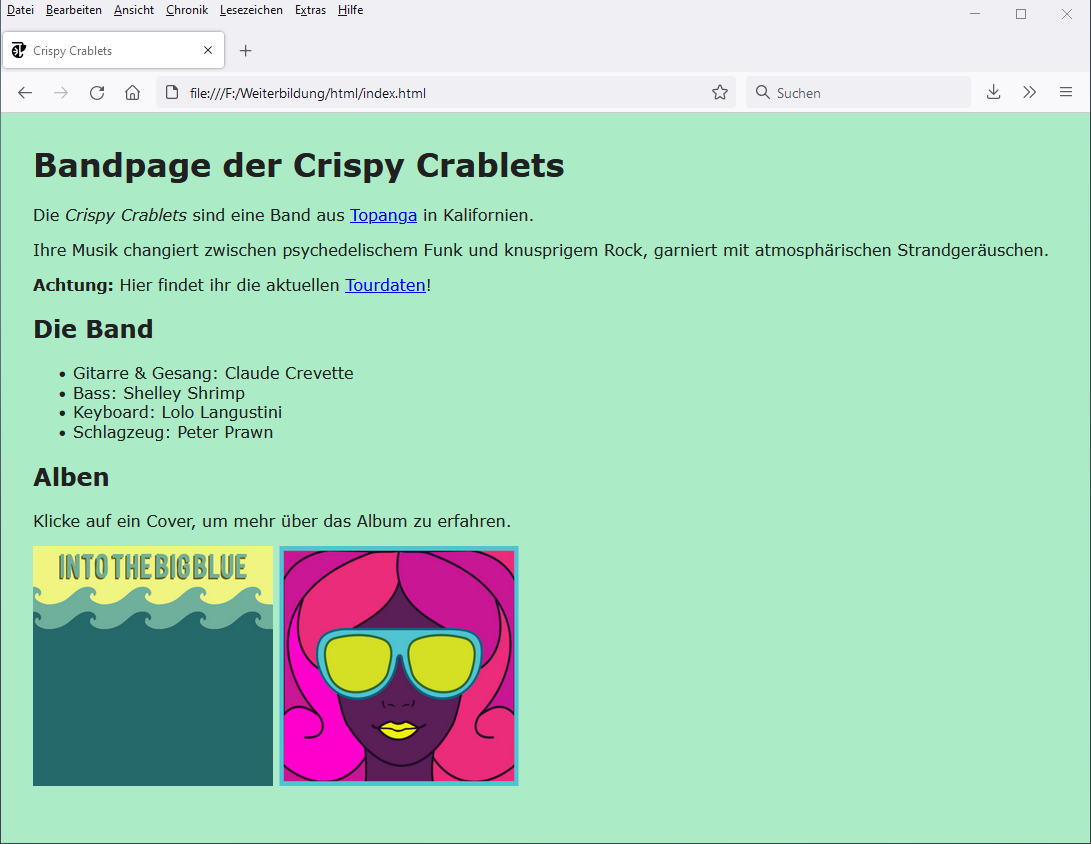
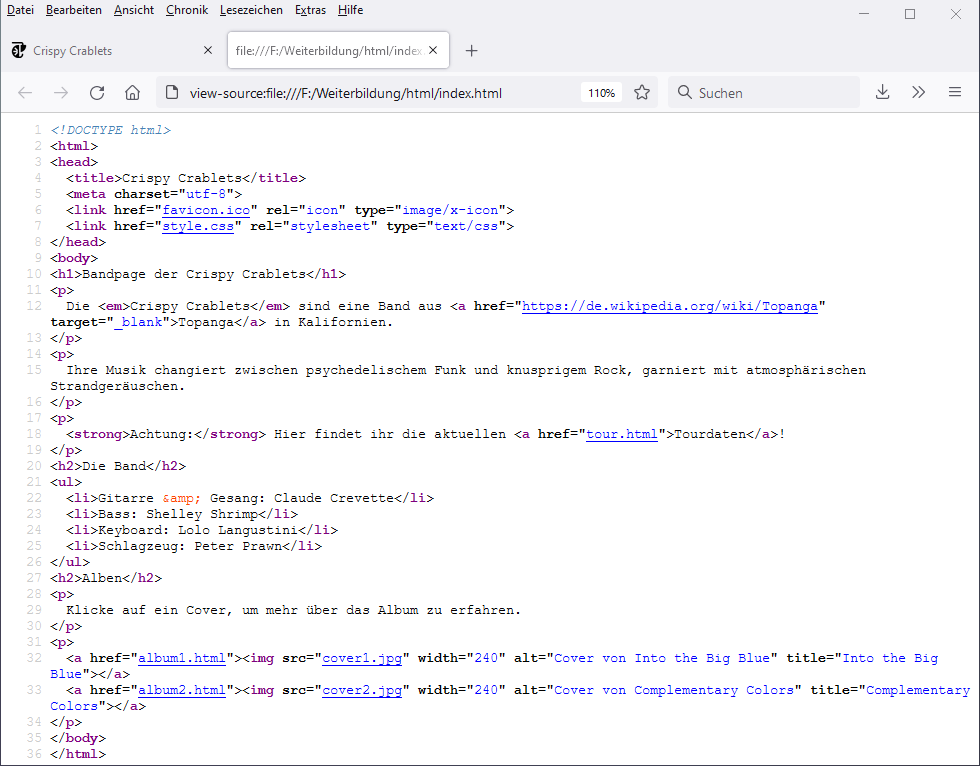
Im Quelltext lassen sich ab Zeile 10 alle Textinhalte der Seite wiederfinden. Dabei lässt sich erkennen, dass Textabschnitte durch bestimmte Zeichenfolgen markiert sind, die ihnen eine spezielle Bedeutung verleihen – beispielsweise in Zeile 10:
<h1>Bandpage der Crispy Crablets</h1>
Hier stehen zu Beginn und am Ende der Zeile die Zeichenfolgen <h1> und </h1>, durch die der Beginn und das Ende einer Überschrift markiert wird (“h1” steht für dabei für heading level 1). Solche Zeichenfolgen in spitzen Klammern werden als Auszeichnungen oder Tags bezeichnet (engl. tag = Markierung, Etikett). Tags treten meistens paarweise in Form eines “öffnenden” und eines “schließenden” Tags auf und umschließen einen Inhalt, der durch die Tags semantisch beschrieben wird.
Tags
Tags sind also bestimmte Zeichenfolgen in HTML, mit denen sich Textteile und Abschnitte mit bestimmten Bedeutungen versehen lassen, die durch den Browser interpretiert werden. Mittels Tags lassen sich unter anderem die Inhalte der Seite gliedern. Im Beispiel sind mehrere solcher Tags zu finden:
Überschriften:
Die Hauptgliederung ist durch Überschriften verschiedener Stufen beschrieben. Neben einer Überschrift erster Stufe für den Seitentitel, die durch die Tags <h1> und </h1> markiert ist (Zeile 10), kommen auch auch Überschriften zweiter Stufe mit <h2> und </h2> als Abschnittstitel vor (Zeile 20 und 27).
<h1>Bandpage der Crispy Crablets</h1>
...
<h2>Die Band</h2>
...
<h2>Alben</h2>
...
Absätze:
Die Textabsätze sind durch die Tags <p> und </p> (für paragraph) markiert, siehe z. B. Zeile 11–19:
<p>
Text im ersten Absatz
</p>
<p>
Text im zweiten Absatz
</p>
<p>
Text im dritten Absatz
</p>
Liste:
Die Liste wird durch die Tags <ul> und </ul> (für unordered list) eingeleitet und abgeschlossen wird (Zeile 21 und 26), während die einzelnen Listeneinträge innerhalb der Liste durch die Tags <li> und </li> (für list item) gekennzeichnet sind (Zeile 22–25):
<ul>
<li>Erster Listeneintrag</li>
<li>Zweiter Listeneintrag</li>
<li>Dritter Listeneintrag</li>
<li>Vierter Listeneintrag</li>
</ul>
Wenn Sie die Beispiel-Webseiten durchstöbern, finden Sie auf den beiden Seiten, die über die Cover-Bilder verlinkt sind, weitere Listen, in denen die Einträge nummeriert dargestellt werden. Hier besteht der einzige Unterschied darin, dass die Liste durch die Tags <ol> und </ol> (für ordered list) beschrieben wird.
Betonter Text:
Daneben finden sich auch Auszeichnungen, um Textteile innerhalb von Absätzen zu betonen, z. B. die Tags <em> und </em> (für emphasized) zu Beginn des ersten Absatzes (Zeile 12):
Die <em>Crispy Crablets</em> sind eine Band aus ...
und die Tags <strong> und </strong> für den stark betonten Text zu Beginn des dritten Absatzes (Zeile 18):
<strong>Achtung:</strong> Hier findet ihr die aktuellen ...
Hyperlink:
Hyperlinks werden durch die Tags <a> und </a> (für anchor) markiert, wobei zwischen den Tags der “anklickbare” Seiteninhalt steht (siehe z. B. Zeile 18):
<a href="tour.html">Tourdaten</a>
Am Beispiel des Hyperlinks ist zu sehen, dass eine Auszeichnung auch zusätzliche Informationen enthalten kann – in diesem Fall wird die Ziel-URL, auf die der Hyperlink verweist, im öffnenden Tag nach href= angegeben (auf diesen Fall wird unter HTML-Attribute genauer eingegangen).
In allen Beispielen ist außerdem erkennbar, dass sich Textauszeichnungen unterscheiden lassen, die vom Browser als Absätze bzw. voneinander abgesetzte “Blöcke” innerhalb der Seite dargestellt werden (z. B. Überschriften, Textabsätze oder Listen, aber auch Tabellen oder Bilder), und Auszeichnungen für Textabschnitte, die im Fließtext dargestellt werden (z. B. betonte Textteile oder Hyperlinks im Text).
Außerdem finden sich noch weitere Tags außerhalb des eigentlichen Seiteninhalts im HTML-Dokument: So wird das Dokument selbst beispielsweise durch das Tag <html> eingeleitet (Zeile 2) und durch </html> abgeschlossen (Zeile 36). Im nächsten Abschnitt werden wir einen systematischen Blick auf die Grundstruktur von HTML-Dokumenten, sowie Syntax und Semantik der HTML-Tags werfen.
HTML-Dokumente
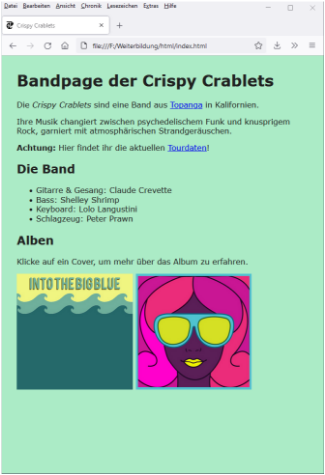
Zunächst fassen wir kurz zusammen, was wir anhand der Beispiel-Webseite gelernt haben: Ein HTML-Dokument beschreibt einen strukturierten Text, der unter anderem Überschriften, Absätze, Bilder, Listen und Tabellen sowie Hyperlinks enthalten kann. Dazu werden Textteile mit Tags ausgezeichnet, wodurch der Text in Elemente unterschiedlicher Bedeutung gegliedert wird. Die folgenden Abbildungen stellen die jeweiligen Abstraktionsstufen für das Beispiel grafisch dar:

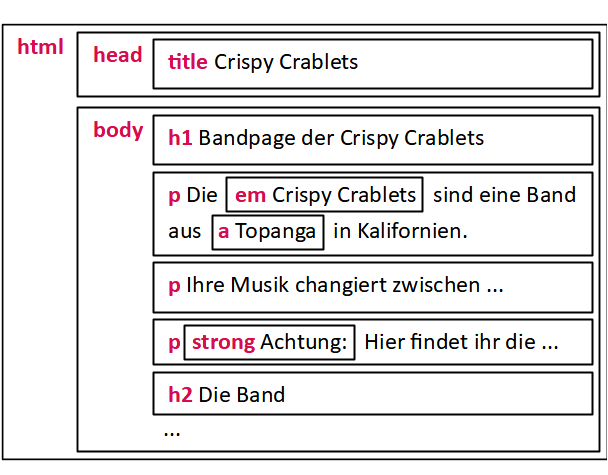

Grundgerüst
Eine HTML-Datei hat immer den folgenden grundlegenden Aufbau:

In der ersten Zeile steht die Dokumenttyp-Deklaration, die dem Browser die Art des Dokuments mitteilt. Die Angabe <!DOCTYPE html> sagt aus, dass es sich um ein HTML5-Dokument handelt.3
Das HTML-Dokument besteht immer aus zwei Teilen:
- dem Dokumentenkopf, der Informationen über das Dokument (“Metadaten”) enthält, z. B. den Titel der Seite oder die verwendete Zeichencodierung,
- dem Dokumentenrumpf, der die vom Browser dargestellten Seiteninhalte.
Dadurch hat jedes HTML-Dokument dasselbe Grundgerüst:
- Es beginnt mit dem Tag
<html>und endet mit dem Tag</html>. Diese Tags legen den gesamten dazwischenliegenden Dateiinhalt als HTML-Dokument fest. - Nach
<html>beginnt der Dokumentenkopf mit<head>und endet mit</head>. Dazwischen stehen die Metadaten, beispielsweise hier der Seitentitel (markiert durch die Tags<title>und</title>) und die Zeichencodierung des Dokuments (für HTML5 üblicherweise UTF-8). - Nach
</head>beginnt der Dokumentenrumpf mit<body>und endet mit</body>, direkt vor</html>. Dazwischen stehen die eigentlichen Seiteninhalte.
Die Informationen, die im Dokumentenkopf stehen, werden nicht innerhalb der Seite im Browser dargestellt, ggf. aber an anderer Stelle – der Seitentitel wird beispielsweise üblicherweise in der Kopfzeile des Browserfensters dargestellt, und im Dokumentenkopf lässt sich auch ein Symbolbild (“Favicon”) für die Webseite (z. B. für Lesezeichen) festlegen (siehe Weitere HTML-Elemente im Dokumentenkopf).
HTML-Elemente
Die durch Tags markierten Textteile – also die Einheiten aus öffnendem Tag, Inhalt und schließendem Tag – stellen die Grundbausteine dar, aus denen das HTML-Dokument zusammengesetzt ist und werden daher als HTML-Elemente bezeichnet. Dabei werden unterschiedliche Tag-Bezeichner verwendet, um verschiedene Typen von HTML-Elementen zu beschreiben – z. B. html für das Dokument an sich, body für den Dokumentenrumpf, p für einen Absatz oder a für einen Hyperlink.

Ein HTML-Element ist immer nach demselben Schema aufgebaut: Es beginnt mit einem öffnenden Tag der Form <Tag-Name>, gefolgt vom Inhalt des Elements, und wird durch ein schließendes Tag
der Form </Tag-Name> beendet. Der Inhalt kann dabei reiner Text sein, aber auch weitere HTML-Elemente enthalten – HTML-Elemente können also “ineinander verschachtelt” werden.
Daneben gibt es auch HTML-Elemente ohne Inhalt, die nur aus einem einzelnen Tag der Form <Tag-Name> bestehen. Beispielsweise stellt <br> ein einfaches HTML-Element ohne Inhalt dar, nämlich einen Zeilenumbruch im Fließtext.
Welche HTML-Elemente an welcher Stelle im HTML-Dokumente zulässig sind und auf welche Weise HTML-Elemente ineinander verschachtelt werden dürfen, wird dabei durch die HTML-Spezifikation geregelt (siehe Validierung von HTML). In vielen Fällen erschließen sich diese Regeln aber relativ intuitiv aus der Bedeutung der Elemente: So darf das HTML-Element <title>, das den Seitentitel angibt, nur im <head>-Element (also im Dokumentenkopf) stehen, während HTML-Elemente wie <h1> für Überschriften oder <p> für Textabsätze nur im <body>-Element (also im Seiteninhalt) erlaubt sind.Listeneinträge mit <li> machen dagegen nur innerhalb von Listen Sinn, also z. B. im Inhalt von <ol>-Elementen.
HTML-Attribute
Die meisten HTML-Elemente besitzen Attribute, über die bestimmte Eigenschaften für das Element festgelegt werden können. Bei einem Hyperlink-Element <a> gibt beispielsweise der Inhalt an, wie der Hyperlink im Browser dargestellt wird (hier durch den Text “Topanga”), während die Ziel-URL über ein Attribut namens href (kurz für hyperlink reference) festgelegt wird:

Die Zuweisung von Werten zu Attributen erfolgt immer im öffnenden Tag in der Form Attributname = Wert.
Für einige Attribute wie href muss ein Wert angegeben werden, damit das HTML-Element sinnvoll interpretiert werden kann. Andere Attribute sind optional – wenn kein Wert explizit zugewisen wird, wird ein Standardwert verwendet.
Ein weiteres Beispiel für HTML-Elemente mit Attributen (in diesem Fall ohne Inhalt) ist das HTML-Element <img>, mit dem sich Bilder in Webseiten einbinden lassen:

- Über das Attribut
srcwird die Quell-URL der Bilddatei angegeben. Für dieses Attribut muss ein Wert angegeben werden, während die folgenden Attribute optional sind. - Mit dem Attribut
widthkann die gewünschte Bildbreite zur Darstellung festgelegt werden. Ist das Bild größer oder kleiner, wird es vom Browser zur Darstellung entsprechend skaliert. Alternativ kann auch die gewünschte Bildhöhe mitheightfestgelegt werden. - Mit dem Attribut
altkann eine Bildbeschreibung als Alternativtext festgelegt werden, der statt des Bildes angezeigt wird, wenn das Bild nicht geladen werden kann. - Mit dem Attribut
titlekann ein Text festgelegt werden, der als “Popup” erscheint, wenn sich der Mauszeiger über dem Bild befindet.
HTML-Attribute sind also benannte Eigenschaften von HTML-Elementen, denen sich Werte zuweisen lassen, wodurch sich das Verhalten der HTML-Elemente genauer steuern lässt (ähnlich den Attributen von Scratch-Objekten in der Visuellen Programmierung). Welche Attribute welches Element besitzt, welche Werte für welche Attribute zulässig sind und was sie bedeuten, ist für jedes HTML-Element in der HTML-Spezifikation festgelegt und lässt sich auch in HTML-Referenzen wie z. B. bei W3Schools nachlesen.
URLs in Webseiten
Mit Hyperlinks und Bildern haben wir zwei HTML-Elemente kennengelernt, die Verknüpfungen zu anderen Dokumenten beschreiben. In beiden Fällen wird die Verknüpfung dadurch spezifiziert, dass die URL der verknüpften Datei als Wert für ein bestimmtes Attribut festgelegt wird (href bei Hyperlinks, src bei Bildern).
Hierbei muss zwischen zwei Arten von URL-Angaben unterschieden werden: absoluten URL-Angaben und relativen URL-Angaben. Betrachten Sie dazu die beiden Hyperlinks, die in der Beispiel-Webseite index.html vorkommen:
- Eine absolute URL wie beispielsweise
https://de.wikipedia.org/wiki/Topanga(Zeile 12) stellt eine vollständige Webadresse dar, die auf eine Datei im Internet verweist. - Eine relative URL wie beispielsweise
tour.html(Zeile 18) stellt dagegen eine Webadresse dar, die relativ zum Dateipfad auf dem Webserver angegeben ist, unter dem die Webseite erreichbar ist, in der diese URL verwendet wird.
Im zweiten Fall wird also erwartet, dass sich die Datei tour.html im selben Ordner auf dem Webserver befindet wie die Datei index.html, in welcher der Hyperlink mit dieser URLs vorkommt. Dasselbe gilt für die URLs der Bilddateien (Zeile 32–33), die ebenfalls im selben Verzeichnis liegen. Angenommen, die Bilder würden in einen Unterordner images verschoben werden. In diesem Fall müssten die URLs in den src-Attributen geändert werden zu “images/cover1.jpg” bzw. “images/cover2.jpg”.
Üblicherweise werden Verknüpfungen zu Dateien, die auf demselben Webserver liegen, in relativer Form angegeben, während Verknüpfungen zu Dateien, die auf anderen Webservern liegen in absoluter Form angegeben werden.
Vertiefung: Objektmodell
Da ein HTML-Dokument aus ineinander verschachtelten HTML-Elementen und Textelementen besteht, lässt sich seine Grundstruktur auch als Baumstruktur darstellen, in der jeder Knoten ein HTML-Element repräsentiert, z. B. eine Überschrift, einen Absatz oder einen Hyperlink. Die Kindknoten eines HTML-Elements sind dabei die Elemente, die in seinem Inhalt liegen. Das Element <html> repräsentiert dabei den Wurzelknoten, der genau zwei Kindknoten besitzt (<head> und <body>), die jeweils weitere, im Inhaltsteil auch beliebig tief weiterverzweigte Knoten enthalten. Auch Textteile, die als Inhalt von HTML-Elementen auftreten, stellen Knoten in diesem Baum dar.
Die HTML-Elemente (und Text-Elemente), aus denen ein HTML-Dokument besteht, lassen sich als Objekte im Sinne der Programmierung betrachten: Sie haben Attribute mit bestimmten Werten, durch die ihre Eigenschaften festgelegt werden, und stehen entsprechend der Baumstruktur in Beziehung zueinander. Im Webbrowser werden HTML-Dokumente intern tatsächlich auf diese Weise repräsentiert: Beim Lesen eines HTML-Dokuments wird im Speicher ein Baum von Objekten erzeugt, den der Browser zur Präsentation der Seite verwendet. Diese Darstellung wird auch als Document Object Model (kurz DOM, engl. für “Dokumenten-Objekt-Modell”) bezeichnet.4
Webseiten erstellen
Um eine einfache Website mit HTML zu erstellen, benötigen Sie nur einen Texteditor zum Bearbeiten der HTML-Dateien und einen Webbrowser zum Anzeigen der Seiten. Sie benötigen keinen Webserver, der Ihre Dateien über das Internet zur Verfügung stellt, sondern können die Dateien einfach lokal auf Ihrem Rechner speichern und bearbeiten.5
Legen Sie zunächst einen Ordner auf Ihrem Rechner an, in dem Sie die HTML-Dateien und andere Dateien (z. B. Bilder) für Ihre Website speichern. Erstellen Sie dort eine neue Textdatei mit der Dateiendung .html (zum Beispiel homepage.html oder index.html6), öffnen Sie sie im Texteditor und fügen Sie das Grundgerüst als Inhalt ein (den Seitentitel können Sie durch einen eigenen, passenden Titel ersetzen):
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Seitentitel</title>
</head>
<body>
</body>
</html>
Achten Sie darauf, dass UTF-8 als Zeichencodierung verwendet wird. Alternativ können Sie die HTML-Datei homepage.html mit dem Grundgerüst auch hier als Vorlage herunterladen und in Ihrem Arbeitsordner speichern: Download
Im Dokumentenrumpf können Sie nun eigenen Inhalt ergänzen, zum Beispiel Überschriften und Textabsätze. Eine Überblick über grundlegende HTML-Elemente, die Ihnen beim Erstellen erster eigener Webseiten helfen können, finden Sie im Anhang unter HTML-Referenz.
Öffnen Sie die Datei nun in einem Webbrowser, um die grafische Darstellung der Seite präsentiert zu bekommen.
Generell ist es bei der Entwicklung von Webseiten im Texteditor hilfreich, sowohl den Editor als auch die Browseransicht gleichzeitig in zwei nebeneinander auf Ihrem Desktop positionierten Fenstern geöffnet zu haben, damit Sie Änderungen an der Textdatei schnell visuell überprüfen können. Speichern Sie dazu nach einer Änderung die Textdatei und aktualisieren Sie dann die Browseransicht der Webseite (z. B. in Firefox die Taste F5 drücken).
Wenn Sie Verknüpfungen zu anderen Webseiten oder Bildern erstellen, die in Ihrem Arbeitsordner liegen, reicht als URL der Dateiname. Wenn Sie beispielsweise ein Bild in eine Webseite einfügen möchten, das in einer Datei leuchtturm.jpg gespeichert ist, kopieren Sie die Datei den Ordner, in dem auch die entsprechende HTML-Datei liegt, und fügen Sie ein HTML-Element <img> zum Seiteninhalt hinzu, z. B.:
<img src="leuchtturm.jpg" alt="Bild eines Leuchtturms">
Als umfangreicheres Beispiel können Sie auch die Beispiel-Website aus der Einleitung auf Ihren Rechner herunterladen, untersuchen und verändern: Download
Entwicklungsumgebungen
Prinzipiell können Sie jeden einfachen Texteditor, der auf Ihrem Rechner installiert ist, zur Bearbeitung von HTML-Dateien verwenden. Einige Texteditoren sind aber geeigneter als andere, da sie über nützliche Funktionen zur HTML-Bearbeitung verfügen.
Die meisten Texteditoren verwenden Syntax Highlighting für HTML, heben also spezielle HTML-Bestandteilen wie Tags, Attributnamen oder -werte im Text durch spezielle Farben oder Formatierungen hervor, was die Übersichtlichkeit des Quelltextes erhöht.
Einige Texteditoren beherrschen darüber hinaus Code-Vervollständigung, dass heißt, dass sie während der Eingabe Vorschläge zur Textergänzung machen, wenn Sie HTML-Code erkennen, zum Beispiel:
- Wenn Sie
<seingeben, erscheint eine Liste, in der alle Tag-Namen, die mit “s” beginnen, ausgewählt werden können. - Wenn Sie
<agefolgt von einem Leerzeichen eingeben, erscheint eine Liste, in der alle Attribute des Elements ausgewählt werden können. - Wenn Sie das Tag
<h1>eingegeben haben, erscheint automatisch das dazu passende schließende Tag</h1>.
Fortgeschrittenere Editoren enthalten manchmal auch eine integrierte Browservorschau, die während der Eingabe automatisch aktualisiert wird, so dass Sie den visuellen Effekt einer Änderung im Quelltext sofort überprüfen können.
Eine Liste von Texteditoren mit solchen Funktionen finden Sie in der Linksammlung bei den Software-Werkzeugen. Für Windows ist Notepad++ aufgrund seiner Einfachheit empfehlenswert. Unter Linux und iOS verfügt der vorinstallierte Standard-Texteditor in der Regel bereits über Syntax Highlighting und Code-Vervollständigung für HTML.
Online-Editoren
Daneben finden Sie im Internet auch eine Reihe von Online-Entwicklungsumgebungen für kleinere HTML-Projekte, die einfach im Webbrowser geöffnet werden können und nicht auf Ihrem Rechner installiert werden müssen. Diese Tools besitzen in der Regel eine integrierte Browservorschau und ermöglichen es zum Teil auch, online auf die erstellten Websites zuzugreifen – das heißt, sie können von anderen Personen im Webbrowser geöffnet werden, statt nur lokal auf Ihrem Rechner verfügbar zu sein.
Die E-Learning-Webseite W3Schools stellt beispielsweise für ihre HTML/CSS-Tutorials einen sehr einfachen Online-Editor zum Bearbeiten und Anzeigen einzelner HTML-Seiten bereit.
In der Online-Entwicklungsumgebung Glitch lassen sich Websites erstellen, die aus mehreren HTML-Seiten sowie weiteren Dateien (z. B. Bilder, CSS-Dateien) bestehen. Die erstellten Websites können über einen öffentlichen Link von jedem angesehen und “remixt” werden, so dass sich Glitch auch im Rahmen des Schulunterrichts zum Bereitstellen von Webseiten eignet, die durch die Schülerinnen und Schüler angepasst, korrigiert oder erweitert werden sollen.
Sie finden Links zu Glitch und weiteren Online-Editoren in der Linksammlung bei den Software-Werkzeugen.
HTML-Inspektoren
Im Aufbau
Validierung
Damit HTML-Dokumente sinnvoll interpretiert werden können, müssen sie logisch und strukturell korrekt sein. Wie korrekter HTML-Quellcode aussieht, ist dabei durch Spezifikationen7 der Hypertext Markup Language festgelegt. HTML-Quellcode, der sich an alle Konventionen und Spezifikationen hält, wird als valide bezeichnet, die Überprüfung als Validierung.
Die offiziellen Spezifikationen für HTML werden vom World Wide Web Consortium (W3C) und der Web Hypertext Application Technology Working Group (WHATWG) entwickelt.8 Darin wird unter anderem festgelegt:
- welche Grundstruktur ein valides HTML-Dokument hat,
- welche Attribute für bestimmte HTML-Elemente erlaubt sind,
- welche Attribute optional sind und welche zwingend benötigt werden,
- welche HTML-Elemente innerhalb von welchen anderen HTML-Elemente erlaubt sind,
- welche HTML-Elemente und -Attribute veraltet sind und nicht mehr genutzt werden sollten,
- wie ein Webbrowser HTML-Elemente mit bestimmten Eigenschaften interpretieren sollte.
Dabei gibt es Unterschiede zwischen verschiedenen Versionen von HTML. Die HTML-Version eines HTML-Dokuments wird durch die Angabe des Dokumenttyp mit <!DOCTYPE …> zu Beginn festgelegt.
Ein valides HTML-Dokument besteht immer aus der Dokumenttyp-Deklaration und den Elementen <html>, <head>, <title> und <body> (siehe Grundgerüst).
Beispiele für eine valide Struktur von HTML-Elementen im Seiteninhalt sind etwa:
- Listeneinträge (
<li>) nur innerhalb von Listen (<ul>,<ol>) vorkommen dürfen, - innerhalb eines Paragraphen (
<p>) keine gruppierenden Elemente wie Listen (<ul>,<ol>) vorkommen dürfen.
Beispiele für grundlegende Vorgaben, wie Webbrowser mit HTML-Elementen umzugehen haben, sind:
- Das Ziel eines Hyperlinks (
<a>) soll in einem neuen Fenster geöffnet werden, wenn das Attributtargetden Wert"_blank"hat. - Für ein Bild (
<img>) soll dessen Alternativtext (Wert des Attributsalt) angezeigt werden, wenn das Bild nicht geladen werden konnte.
So können sich Webentwicklerinnen und -entwickler darauf verlassen, dass ihre HTML-Dokumente auf eine vorgegebene Weise von Webbrowsern interpretiert und dargestellt werden, solange sie sich an die entsprechenden Vorgaben halten.
Die meisten Webbrowser können HTML-Dokumente aber auch dann einigermaßen sinnvoll darstellen, wenn der HTML-Quellcode nicht vollständig valide ist, also in einem gewissen Umfang logische oder strukturelle Fehler enthält. In solchen Fällen ist aber nicht gesichert, ob die Seite wie erwartet dargestellt wird, weswegen solche Fehler in der Praxis möglichst vermieden werden sollten. Typische Fehler sind:
- Ein öffnendes Tag wird an der falschen Stelle oder gar nicht geschlossen.
- Ein Element, das in den Inhaltsbereich (
<body>) gehört, wird versehentlich im Kopf der HTML-Datei (<head>) definiert. - Die Namen von Tags oder Attributen enthalten Buchstabendreher oder andere Schreibfehler.
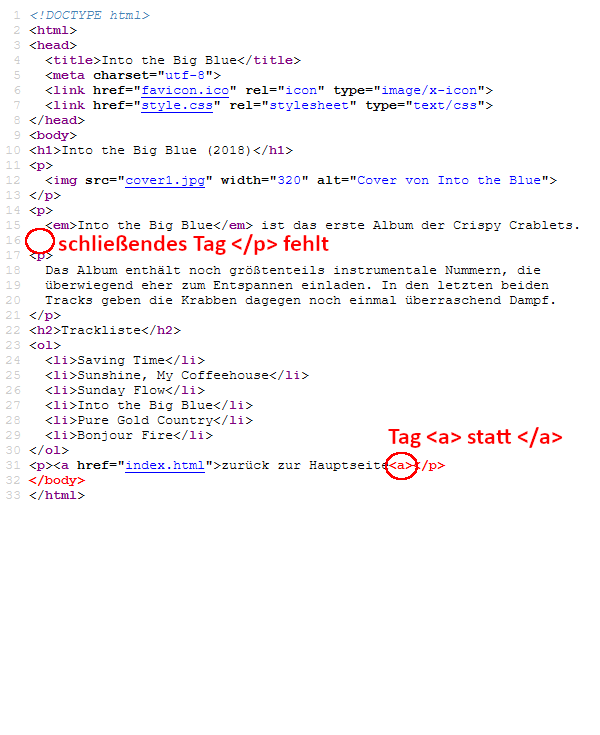
Tipp: Um Fehler schneller zu finden, ist es sinnvoll, HTML-Quelltext übersichtlich zu strukturieren. Die folgende Abbildung zeigt sehr chaotischen Quelltext, in dem es schwer ist, die vorhandenen Fehler ausfindig zu machen (links). In der aufgeräumten Version (rechts) lässt sich dagegen schnell feststellen, dass zwei schließende Tags fehlen bzw. syntaktisch falsch angegeben sind:

W3C Online-Validator
Tool: Um zu überprüfen, ob ein HTML-Dokument valide ist, kann der Online-Validator des W3C verwendet werden: https://validator.w3.org
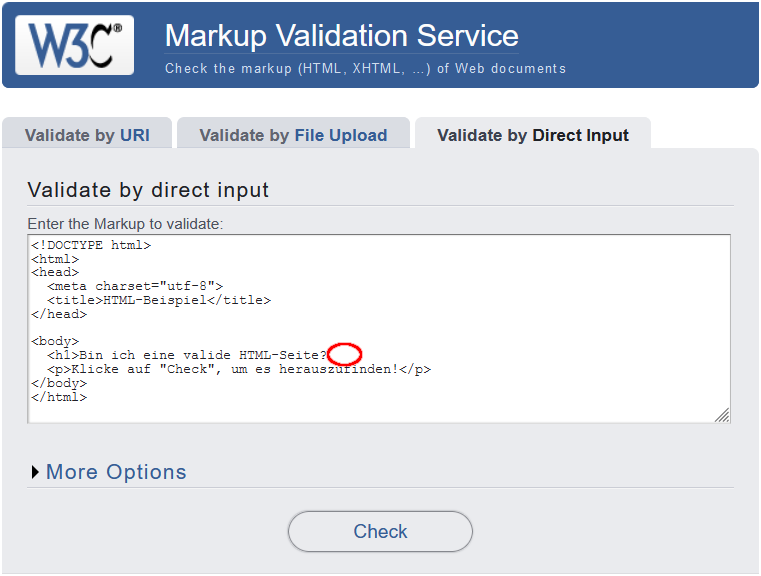
In diesem Tool kann eine HTML-Datei hochgeladen, die URL einer HTML-Datei im Internet eingegeben oder HTML-Quellcode in ein Texteingabefeld eingefügt werden und validiert werden. Erkannte Fehler und Warnungen werden anschließend angezeigt.
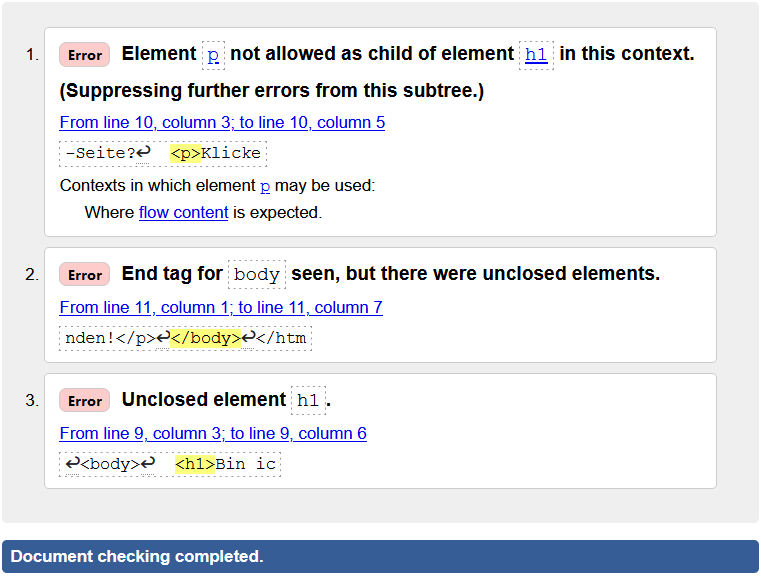
Die folgende Abbildung zeigt, wie HTML-Quellcode über das Texteingabefeld validiert wird (links), wobei ein schließendes Tag fehlt. Nachdem auf die Schaltfläche “Check” geklickt wird, erscheint ein Validierungsbericht (rechts), in dem als Fehler das fehlende Tag <\h1> (3.), sowie zwei Folgefehler (1. und 2.) erkannt werden:
- Da das Tag
<h1>nicht geschlossen wird, wird das folgende Absatz-Element<p>als Kindknoten des Überschrift-Elements<h1>interpretiert, was aber laut HTML-Spezifikation nicht erlaubt ist. - Es wird erkannt, dass beim Schließen des
<body>-Tags innerhalb des Dokumentenrumpfes Elemente vorkommen, die noch nicht geschlossen wurden (nämlich<h1>).
HTML-Referenz
Hier finden Sie einen kurzen Überblick über die wichtigsten, grundlegenden HTML-Elemente zum Erstellen einfacher Webseiten, jeweils nach Kategorien aufgeteilt. Umfangreichere Listen zum Weiterlernen finden Sie bei W3Schools und SELFHTML.
Dokument
Diese HTML-Elemente legen die Grundstruktur des HTML-Dokuments fest.
| Element | Beschreibung |
|---|---|
<html> </html> | HTML-Dokument |
<head> </head> | Dokumentenkopf mit Metadaten, z. B. Titel der Seite |
<body> </body> | Dokumentenrumpf mit Seiteninhalt |
Text
Diese HTML-Elemente dienen zur Textgliederung und Auszeichnung von Textteilen im Seiteninhalt.
| Element | Beschreibung |
|---|---|
<h1> </h1> … <h6> </h6> | Überschriften (Stufe 1 bis 6) |
<p> </p> | Textabsatz (Paragraph) |
<br> | Zeilenumbruch (engl. break line) |
<hr> | Horizontale Trennlinie (engl. horizontal ruler) |
<em> </em> | Betonter Text (engl. emphasized), in der Regel kursiv dargestellt9 |
<strong> </strong> | Stark betonter Text, in der Regel fett dargestellt10 |
<code> </code> | Quellcode, in der Regel mit Festbreitenschrift dargestellt11 |
<q> </q> | Zitat im Fließtext |
<blockquote> </blockquote> | Zitat als Absatz |
Verknüpfungen
Diese HTML-Elemente dienen zum Verknüpfen von Webseiten untereinander und zum Einfügen von Bilddateien in den Seiteninhalt. Die URLs und weitere (optionale) Informationen werden über die Attribute der Elemente festgelegt.
| Element | Beschreibung | Attribute | Beschreibung |
|---|---|---|---|
<a href="URL"> </a> | Hyperlink | href="URL" | legt das Ziel der Verknüpfung fest |
optional: target="_blank" | legt fest, dass das Ziel in einem neuen Fenster geöffnet werden soll | ||
<img src="URL"> | Bild | src="URL" | legt die URL der Bilddatei fest |
optional: Attributen alt="Text" | legt Alternativtext fest, der angezeigt wird wenn das Bild nicht geladen werden konnte | ||
optional: width="Zahl" und/oder height="Zahl" | legt die gewünschte Bildgröße zur Darstellung fest | ||
optional: title="Text" | legt Beschreibungstext fest, der beim Draufzeigen mit der Maus angezeigt wird |
Listen und Tabellen
Listen und Tabellen im Seiteninhalt werden durch verschachtelte HTML-Elemente beschrieben.
| Element | Beschreibung |
|---|---|
<ul> </ul> | Liste ohne Nummerierung |
<ol> </ol> | Nummerierte Liste |
<li> </li> | Listeneintrag innerhalb einer Liste (innerhalb <ul> oder <ol>) |
<table> </table> | Tabelle |
<tr> </tr> | Tabellenzeile in einer Tabelle (innerhalb <table>) |
<td> </td> | Datenzelle in einer Tabellenzeile (innerhalb <tr>) |
<th> </th> | Spaltenüberschrift in einer Tabellenzeile (innerhalb <tr>), in der Regel die Datenzellen der ersten Tabellenzeile |
Die Art der Nummerierung für die Listeneinträge in einem <ol>-Element kann durch das HTML-Attribut ``
Metadaten
Die folgenden HTML-Elemente legen Informationen über das Dokument fest und kommen nur im Dokumentenkopf vor.
| Element | Beschreibung |
|---|---|
<link> | Externe Datei im Dokumentenkopf einbinden mit Attributen href="URL" zum Festlegen der Quelle und rel=Relation für die Bedeutung der externen Datei, z. B. rel="stylesheet" für eine CSS-Datei oder rel="icon" für das Favicon12 |
<meta> | Weitere Metadaten, z. B. <meta charset="utf-8"> zum Festlegen der Zeichencodierung als UTF-8 |
Vertiefung: HTML-Entities
Da im HTML-Quellcode bestimmte Zeichen eine Sonderbedeutung haben – insbesondere die spitzen Klammern < und >, die zur Kennzeichnung von Tags verwendet werden – müssen solche Zeichen auf eine andere Weise dargestellt werden, wenn sie im Seiteninhalt als Textzeichen vorkommen sollen.
Beispiel:
Angenommen, der HTML-Quellcode enthält die folgende Zeile, in der die Bedeutung des HTML-Elements <em> erläutert wird:
<p>Das Tag <em> betont Text und wird durch das Tag </em> geschlossen.</p>
Der entsprechende Absatz wird vom Browser aber folgendermaßen dargestellt, da die Zeichenfolgen <em> und </em> natürlich als HTML-Tags interpretiert werden:
Das Tag betont Text und wird durch das Tag geschlossen.
Um solche Sonderzeichen als reine Textzeichen darzustellen, werden in HTML bestimmte alternative Zeichenfolgen verwendet, die sogenannten HTML-Entities. Diese werden in der Form &Entity-Name; angegeben, wobei die Entity-Namen meistens Kurzformen der repräsentierten Zeichen darstellen. Die HTML-Entities für die Zeichen < und > sind beispielsweise < (kurz für less than = kleiner gleich) und > (kurz für greater than = größer gleich).
Da das Zeichen & eine HTML-Entity einleitet, muss dieses ebenfalls durch eine HTML-Entity ersetzt werden, wenn es als Textzeichen dargestellt werden soll – in diesem Fall durch die Zeichenfolge & (kurz für ampersand = “Kaufmanns-Und”).
HTML-Entities existieren für viele Sonderzeichen, auch für solche, die in HTML keine Sonderbedeutung haben. Das ist hilfreich für Steuerzeichen, die sich nicht direkt per Tastatur eingeben lassen, beispielsweise das geschützte Leerzeichen (kurz für non-breaking space) oder das weiche Trennzeichen ­ (kurz für soft hyphen).13
Alternativ lässt sich jedes Sonderzeichen in HTML auch im Format &#Nummer; mit der Unicode-Nummer des gewünschten Zeichens angeben, z. B. Ä für den Buchstaben Ä.
Die Definition von HTML-Entities ist hauptsächlich dadurch motiviert, dass HTML-Dateien früher in 8-Bit-Zeichencodierungen (in der Regel ISO-8859-1) codiert wurden. Seitdem sich HTML5 als Standard für HTML-Dokumente etabliert hat, wird standardmäßig UTF-8 als Zeichencodierung empfohlen, weswegen HTML-Entities in HTML5-Dokumenten bis auf wenige Ausnahmen kaum noch verwendet werden.
Die folgende Liste zeigt der Vollständigkeit halber einige der vor HTML5 am häufigsten verwendeten HTML-Entities:14
| HTML-Entity | Sonderzeichen |
|---|---|
Ä ä … ü | Umlaute Ä ä … ü |
ß | Eszett-Zeichen ß |
& | Und-Zeichen & (engl. ampersand) |
< > | Spitze Klammern < > (bzw. Vergleichszeichen, engl. less/greater than) |
" | Anführungszeichen " (engl. quotation mark) |
° | Grad-Zeichen ° (engl. degree) |
€ | Euro-Zeichen € |
© | Copyright-Zeichen © |
| Geschütztes Leerzeichen (engl. non-breaking space) |
­ | Weiches Trennzeichen (engl. soft hyphen) |
&#Nummer; | Sonderzeichen mit der angegebenen Referenznummer (dezimal angegeben) |
&#xNummer; | Sonderzeichen mit der angegebenen Referenznummer (hexadezimal angegeben) |
Formale Sprachen, die dieses Grundkonzept verwenden und zu denen auch HTML gehört, heißen daher “Auszeichnungssprachen” (markup languages). ↩︎
Generell empfielt es für den Einstieg in HTML, spezielle didaktisch reduzierte Webseiten zu untersuchen. Die meisten “echten” Webseiten eignen sich eher nicht als Lernbeispiele, da sie sehr umfangreichen, oft automatisch generierten und damit sehr unübersichtlichen HTML-Code enthalten. ↩︎
Wird die Dokumenttyp-Deklaration weggelassen, wird die Webseite zwar in der Regel trotzdem im Webbrowser angezeigt, eventuell aber nicht wie erwartet, da der Webbrowser in dem Fall die verwendete HTML-Version raten muss. ↩︎
Der Begriff HTML DOM bedeutet konkret nicht nur die Darstellung der HTML-Dokuments durch einen Baum von Objekten, sondern beschreibt darüber hinaus eine Programmierschnittstelle, die von Programmiersprachen wie JavaScript genutzt werden, um im Browser geladene HTML-Dokumente dynamisch zu ändern. ↩︎
So ist Ihre Website zwar nicht über das Internet von außen zugänglich, sondern kann nur lokal auf Ihrem Rechner geöffnet werden – für den Anfang reicht das aber, um erste Projekte zu erstellen, anhand derer sich HTML praktisch erlernen lässt. ↩︎
Der Dateiname index.html wird üblicherweise für die Einstiegsseite einer Website verwendet, die aus mehreren HTML-Dateien besteht. ↩︎
Eine Spezifikation im Sinne der Informatik legt die Eigenschaften und die gewünschte Umsetzung einer Technologie (z. B. einer Software, einer Programmiersprache, eines technischen Systems) fest. ↩︎
siehe https://www.w3.org/TR/html5 und https://html.spec.whatwg.org ↩︎
vgl.
<i> </i>für kursiv dargestellten Text (engl. italic) ↩︎vgl.
<b> </b>für fettgedruckten Text (engl. bold) ↩︎vgl.
<tt> </tt>für Text mit Festbreitenschrift (Schreibmaschinen- oder Fernschreiberschrift, engl. teletype) ↩︎Ein Favicon (engl. favorite icon) ist ein kleines Symbolbild für eine Webseite, das im Browser oben neben dem Seitentitel und im Lesezeichenmenü angezeigt wird. ↩︎
Eine Zeile wird bei einem geschützten Leerzeichen nicht umgebrochen, außerdem ersetzt der Webbrowser mehrfache aufeinanderfolgende geschützte Leerzeichen nicht durch ein einzelnes Leerzeichen, wie bei normalen Leerzeichen im HTML-Quelltext. Eine weiches Trennzeichen wird dagegen nur dargestellt, wenn das Wort an dieser Stelle durch einen Zeilenumbruch getrennt wird. ↩︎
siehe auch Listen bei W3Schools und SELFHTML. Eine vollständige Liste aller HTML-Entity-Namen des W3C finden Sie hier:
https://html.spec.whatwg.org/multipage/named-characters.html#named-character-references ↩︎