Datenkompression
Einleitung
Im Alltag sind wir von immer größer werdenden Datenmengen umgeben, die wir auf Rechnern speichern oder durch das Internet schicken. Besonders kritisch sind Mediendaten wie Bilder, Tonaufnahmen und Videos – selbst Ihre Urlaubsfotosammlung würde als Rohdaten gespeichert schnell viele hundert Gigabyte einnehmen. Darüber hinaus müssen von relevanten Daten in regelmäßigen Abständen Sicherungskopien (Backups) erstellt und zum Teil über längere Zeit archiviert werden, was das Problem des Speicherbedarfs noch vergrößert. Aus diesem Grund sind Verfahren zur Datenkompression unerlässlich.
Verfahren zur Datenkompression sind dabei im Grunde nichts anderes als Codierungsverfahren – also Verfahren, die Daten von einer Repräsentation in eine andere umwandeln – mit zwei entscheidenden Eigenschaften:
- Die codierten Daten haben einen geringeren Speicherumfang als die Originaldaten (Kompression).
- Es gibt ein entsprechendes Decodierungsverfahren, mit dem die komprimierten Daten wieder in ihre ursprüngliche Repräsentation umgewandelt werden (Dekompression).
Dabei werden verlustfreie Kompressionsverfahren und verlustbehaftete Kompressionsverfahren unterschieden, je nachdem ob die Originaldaten bei Kompression und anschließender Dekompression exakt oder nur ungefähr wiederhergestellt werden (siehe Kompressionsverlust).
Anwendungen
Datenkompression wird in der Praxis unter anderem in “Packprogrammen” (auch Archivierungs- oder Kompressionsprogramme) verwendet, mit denen sich mehrere Dateien in einem komprimierten Format in eine Archiv-Datei verpacken lassen. Bekannte Dateiformate für solche komprimierten Archive sind etwa ZIP oder RAR (siehe auch Dateiformate). Solche Programme werden immer dann verwendet, wenn größere Datenmengen ein Problem darstellen – beispielsweise um Dateien per E-Mail zu verschicken, auf einer Webseite zum Download anzubieten oder auf einem Datenträger zu sichern.

Daneben wird Datenkompression auch häufig in Dateiformaten zur Codierung von Mediendaten – also Bild-, Audio- und Videodaten – verwendet, wobei hier oft auch verlustbehaftete Kompressionsverfahren zum Einsatz kommen, da hier Informationsverlust zugunsten stärker Speicherreduktion in einem gewissen Umfang tolerierbar ist. Fast alle heute gängigen Mediendateiformate wie JPEG oder PNG für Rastergrafiken, MP3 für Audiodaten oder MPEG für Videos verwenden Datenkompression, da umkomprimierte Mediendaten schnell sehr groß werden.
Kompressionsfaktor
Um zu beschreiben, wie stark Daten komprimiert werden, wird das quantitative Verhältnis zwischen komprimierten und unkomprimierten Daten verwendet.
- Der Kompressionsfaktor gibt an, wie groß die Daten nach der Kompression im Verhältnis zu den Originaldaten sind:
Kompressionsfaktor = komprimierte Datenmenge / originale Datenmenge
Dieser Faktor wird üblicherweise als Dezimalzahl, Prozentzahl oder Verhältnis in der Form “1 zu x” angegeben.
Wird beispielsweise eine Datei von ursprünglich 320 kB Größe auf 80 kB Größe komprimiert, beträgt der Kompressionsfaktor 80 / 320 = 0.25 (bzw. 25% oder 1 zu 4). - Die Kompressionsrate gibt umgekehrt das Verhältnis der originalen Dateimenge zur komprimierten Dateimenge an (im Beispiel also 4 zu 1).
Kompressionsverlust
Bei bestimmten Kompressionsverfahren gehen bei der Codierung und anschließenden Decodierung Teile der Information verloren, die Originaldaten können also nach der Kompression nicht mehr exakt wiederhergestellt werden. Solche verlustbehafteten Verfahren werden überwiegend zur Kompression von Bild-, Video- oder Audiodaten verwendet – dabei wird versucht, nur “unwichtige” Information zu reduzieren, also kleine Bilddetails oder leise Töne, deren Fehlen oder Verfremdung kaum auffällt. Hier lässt sich meistens durch einen Parameter steuern, wie stark die Daten komprimiert werden sollen, wobei mit zunehmender Kompressionsstärke die Bild- oder Tonqualität immer stärker leidet.
Beispiel: Das JPEG-Dateiformat für Rastergrafiken verwendet verlustbehaftete Kompression, deren Stärke sich über einen “Qualitätsfaktor” steuern lässt. Die folgende Übersicht zeigt ein Bild, das mit verschiedenen Qualitätsfaktoren komprimiert wurde, sowie die resultierenden Dateigrößen (in der Vergrößerung der rechten beiden Bilder lassen sich blockartige Bildstörungen erkennen, z. B. auf dem Leuchtturm):
 |  |  |  |  |
| Qualitätsfaktor 90% | Qualitätsfaktor 75% | Qualitätsfaktor 50% | Qualitätsfaktor 25% | Qualitätsfaktor 10% |
| Dateigröße 87 kB | Dateigröße 50.8 kB | Dateigröße 29.8 kB | Dateigröße 17.6 kB | Dateigröße 9.3 kB |
Bei der Kompression anderer Daten wie Textdateien oder Programmcode kommen solche Informationsverluste dagegen nicht in Frage: Hier müssen die Originaldaten aus den komprimierten Daten auf das Bit genau wieder hergestellt werden können. In dieser Lektion werden wir nur solche verlustfreien Kompressionverfahren betrachten.
Im Folgenden werden drei bekannte verlustfreie Kompressionsverfahren vorgestellt, die auch in der Praxis zur Datenkompression in verschiedenen Dateiformaten verwendet werden, und dabei unterschiedliche Grundstrategien verfolgen. Zur Veranschaulichung werden diese Verfahren hier auf kleine Beispiele zur Kompression von Textdaten und Bilddaten angewendet.
In den folgenden Beispielen werden die Ein- und Ausgabedaten der Einfachheit halber meistens als Textzeichen und Dezimalzahlen dargestellt. In der Praxis werden die Ausgabedaten der Kompressionsverfahren aber natürlich binär codiert.
Lauflängencodierung
Die Lauflängencodierung (engl. run-length encoding, kurz RLE) ist ein grundlegendes verlustfreies Kompressionsverfahren für beliebige Daten, das darauf abzielt, längere Wiederholungen von Zeichen zu komprimieren.
Die Idee ist relativ einfach: Statt Daten wie bisher Zeichen für Zeichen zu codieren, wird jeweils das Zeichen und seine “Lauflänge”, also wie oft es wiederholt wird, codiert. Die Ausgabe der Lauflängencodierung besteht dann abwechselnd aus Zeichen und Ganzzahlen.
Zur Kompression werden also die folgenden Schritte wiederholt, bis die Eingabe vollständig verarbeitet wurde:
- Lies solange ein Zeichen x aus der Eingabe, bis ein anderes Zeichen folgt, und zähle dabei, wie oft x nacheinander vorkommt (= Lauflänge N).
- Schreibe das Zeichen x und die Ganzzahl N in die Ausgabe.
Beispiel: Gegeben ist die Zeichenfolge:
A B B A C C C C D E A A A A A E E E E E E E E E
Nach Anwendung der Lauflängencodierung wird daraus (die Lauflängen sind hier blau markiert):
A 1 B 2 A 1 C 4 D 1 E 1 A 5 E 9
Hier reichen 4 Bit zur Codierung der Längenangaben aus. Wenn die 24 Textzeichen mit 8 Bit pro Zeichen codiert werden, erhalten wir einen Datenumfang von 24⋅8 Bit = 192 Bit, für die lauflängencodierten Daten dagegen nur 8⋅8 Bit (Zeichen) + 8⋅4 Bit (Längenangaben) = 96 Bit. Damit reduziert sich der Datenumfang auf 96 / 192 = 50%.
Bei der Dekompression werden also die folgenden Schritte wiederholt, wobei hier die komprimierten Daten als Eingabe abgearbeitet werden:
- Lies ein Zeichen x und eine Ganzzahl N aus der Eingabe.
- Schreibe das Zeichen x N-mal nacheinander in die Ausgabe.
Wie gut sich Daten durch die Lauflängencodierung komprimieren lassen, hängt davon ab, wie wahrscheinlich es ist, dass Zeichen wiederholt vorkommen. Im schlimmsten Fall kann sich der Datenumfang durch die Lauflängencodierung sogar vergrößern, wenn Zeichenwiederholungen selten sind und viele Zeichen einzeln stehen.
Beispiel: Gegeben ist die Zeichenfolge:
A B A C A D E E E E E B A C A
Nach Anwendung der Lauflängencodierung wird daraus:
A 1 B 1 A 1 C 1 A 1 D 1 E 5 B 1 A 1 C 1 A 1
Wenn 8 Bit pro Zeichen und 3 Bit pro Längenangabe verwendet werden, erhalten wir 15·8 Bit = 120 Bit für die unkomprimierten Daten, aber 11·8 Bit (Zeichen) + 11·3 Bit (Längenangaben) = 121 Bit für die lauflängencodierten Daten.
Verbesserte Lauflängencodierung
Aus diesem Grund werden bei der Lauflängencodierung Zeichen nur dann durch das Format Zeichen Lauflänge ersetzt, wenn sie geeignet oft wiederholt vorkommen, z. B. mindestens 3-mal in Folge. Anderenfalls bleiben die Zeichen unverändert.
Nun muss aber in der Ausgabe markiert werden, ob ein Zeichen mit oder ohne Längenangabe vorkommt. Anderenfalls kann bei der Decodierung nicht entschieden werden, ob es sich um ein einzelnes Zeichen oder eine Zeichenwiederholung handelt. Dazu wird üblicherweise ein bestimmtes Zeichen als “Markierungszeichen” ausgewählt. Dieses Zeichen markiert nun in der Ausgabe, dass eine Zeichenwiederholung im Format Zeichen Lauflänge folgt. Kommt in der Eingabe eine Zeichenwiederholung mit ausreichender Länge vor, wird diese also durch das Markierungszeichen, gefolgt vom Zeichen aus der Eingabe und der Länge der Wiederholung ersetzt.
Der Algorithmus zur Lauflängencodierung wird also folgendermaßen angepasst:
- Lies solange ein Zeichen x aus der Eingabe, bis ein anderes Zeichen folgt, und zähle dabei die Lauflänge N.
- Wenn N zu klein ist (z. B. N < 3): Schreibe x N-mal nacheinander in die Ausgabe.
- Anderenfalls: Schreibe Markierungszeichen, x und Lauflänge N in die Ausgabe.
Beispiel: Wir codieren eine Zeichenfolge, die sowohl einzelne Zeichen als auch Zeichenwiederholungen enthält:
A B A C A D E A A A A A E E E E E E E E E B A C C A B A A
Wenn das Zeichen “E” als Markierungszeichen für Zeichenwiederholungen verwendet wird, erhalten wir die folgende Ausgabe:
A B A C A D E E 1 E A 5 E E 9 B A C C A B A A
Die ersten 6 und letzten 8 Zeichen werden unverändert ausgegeben, da sie einzeln oder nur doppelt stehen. Die längeren Wiederholungen der Zeichen “A” und “E” werden im Lauflängenformat ausgegeben. Auch das einzelne Zeichen “E” muss im Lauflängenformat mit Länge 1 ausgegeben werden.
Bei 8 Bit pro Zeichen und 4 Bit pro Längenangabe erhalten wir hier: 14 einfache Zeichen (jeweils 8 Bit) + 3 Zeichenwiederholungen (jeweils 8 + 8 + 4 Bit = 20 Bit) = 172 Bit. Im Vergleich dazu: Bei Lauflängencodierung ohne Markierungszeichen werden je 8 + 4 Bit = 12 Bit für jedes einfache Zeichen und für jede Zeichenwiederholung benötigt, also 15·12 = 180 Bit. Je mehr weitere einzelne Zeichen in den Originaldaten enthalten wären, desto schlechter würde die Lauflängencodierung ohne Markierungszeichen im Vergleich zur verbesserten Version abschneiden.
Der Algorithmus zur Decodierung von lauflängencodierten Daten wird ebenfalls entsprechend angepasst:
- Lies ein Zeichen x aus der Eingabe.
- Wenn x das Markierungszeichen ist:
- Lies ein Zeichen y und eine Ganzzahl N aus der Eingabe.
- Schreibe das Zeichen y N-mal in die Ausgabe.
- Anderenfalls:
- Schreibe das Zeichen x in die Ausgabe.
Beachten Sie: Wenn in der Eingabe das Zeichen vorkommt, das die Rolle des Markierungszeichens übernimmt (hier: E), wird es immer in der Form “Markierungszeichen, Markierungszeichen, Lauflänge” ausgegeben, selbst wenn es einzeln steht. Daher sollte das Markierungszeichen so gewählt werden, dass es möglichst selten in den Eingabedaten vorkommt (bzw. selten einzeln steht). Wenn das Markierungszeichen beliebig gewählt werden kann, muss es zusammen mit den komprimierten Daten gespeichert werden (z. B. als erstes Zeichen zu Beginn), damit es bei der Decodierung bekannt ist.
Lauflängencodierung für Bilder
Die Lauflängencodierung kann natürlich nicht nur auf Textdaten angewendet werden, sondern prinzipiell auf beliebige Daten – beispielsweise auch auf Rasterbilddaten, wobei hier jeweils ein Grauwert oder ein RGB-Wert als einzelnes Zeichen betrachtet wird.
In Praxis zeigt sich, dass die Lauflängencodierung für die Kompression von Textdaten weniger gut geeignet ist, da mehrfache Zeichenwiederholungen in diesen eher selten vorkommen (abgesehen vielleicht von Steuerzeichen wie Leerzeichen oder Tabulatorzeichen bei mehrfach eingerückten Texten). Bei Rasterbilddaten kann sie dagegen sehr gute Ergebnisse erzielen, wenn die Bilder größere Bereiche mit gleicher Farbe und eher wenige Schattierungen/Farbverläufe enthalten.
Beispiel:
Zur Veranschaulichung soll die Lauflängencodierung hier auf ein 8-Bit-Grauwertbild der Größe 10 × 8 Pixel angewendet werden. Die Bilddaten bestehen hier aus 80 Grauwerten, die zeilenweise von oben links nach unten rechts aneinandergereiht werden. Als Markierungszeichen wird hier der Grauwert 0 (hex. 00) festgelegt, für die Codierung der Lauflängen werden 4 Bit verwendet (max. Längenangabe ist also 16).

In der Abbildung steht rechts neben den Bildzeilen, welche Grauwerte (hier im Hexadezimalformat) in der Zeile nacheinander wie oft vorkommen.
Wir erhalten hier das folgende (hier gekürzte) Ergebnis: Die obere Zeile stellt die Grauwerte und ihre Lauflängen in den Bilddaten dar, darunter steht die Ausgabe der Lauflängencodierung (die Längenangaben sind hier wieder als Dezimalzahlen dargestellt, in der “eigentlichen” Ausgabe werden sie als 4-Bit-Binärzahlen codiert).

Bitweise Lauflängencodierung
Wenn die Lauflängencodierung auf Bit-Ebene angewendet wird, also nur die beiden Werte 0 und 1 als Zeichen betrachtet werden, vereinfacht sich das Verfahren. Da Bitsequenzen abwechselnd aus Folgen von Nullen und Einsen bestehen, muss hier in der Ausgabe nicht explizit angegeben werden, welches Zeichen als nächstes folgt: Auf jede Null-Folge folgt eine Eins-Folge und umgekehrt. Daher reicht es bei der bitweisen Lauflängencodierung, die Längen der abwechselnd aufeinanderfolgenden Null- und Eins-Folgen auszugeben. Dabei muss vereinbart werden, ob sich die erste Längenangabe auf eine Null-Folge oder Eins-Folge bezieht (per Konvention üblicherweise auf eine Null-Folge).
Beispiel: Gegeben ist die folgende Bitsequenz (Leerzeichen hier nur zur besseren Übersicht):
1111 1110 0000 0111 1100 0001
Die Lauflängencodierung der Bitfolge ergibt nun die folgende Zahlenfolge:
0, 7, 6, 5, 5, 1
Die Längen der Null-Folgen sind hier der einfacheren Zuordnung halber grau dargestellt, die Längen der Eins-Folgen schwarz. Wenn hier jede Längenangabe als Ganzzahl mit 3 Bit gespeichert wird, erhalten wir als Resultat die folgende Bitsequenz (Leerzeichen hier nur zur besseren Übersicht):
000 111 110 101 101 001
Die Codelänge wurde damit von 24 Bit auf 18 Bit reduziert, also auf 75% der ursprünglichen Codelänge.
Dieses Verfahren lässt sich generell für Daten im Binärformat verwenden, unabhängig davon, was die Daten bedeuten – solange relativ häufig längere Bitfolgen mit demselben Wert erwartet werden. Besonders geeignet ist dieses Verfahren für die Kompression von Schwarz-Weiß-Bildern. Im folgenden Beispiel werden die Pixel eines 8×8-Schwarz-Weiß-Bildes zeilenweise von oben links nach unten rechts per Lauflängencodierung codiert:

Die Lauflängencodierung der Bitfolge ergibt die folgenden 17 Zahlen:
2, 4, 3, 6, 1, 1, 2, 2, 2, 18, 6, 1, 1, 6, 3, 4, 2
Wenn auch hier jede Längenangabe als Ganzzahl mit 3 Bit gespeichert wird, ist die maximal darstellbare Längenangabe 2³ − 1 = 7. Die Zahl 18 muss also durch die Zahlenfolge 7, 0, 7, 0, 4 ersetzt werden. Damit erhalten wir 21 Zahlen und eine Codelänge von 3 ⋅ 21 = 63 Bit. Ingesamt haben wir in diesem Beispiel also nur 1 Bit gespart.
Klarerweise wird die Kompressionsrate aber umso besser, je mehr aufeinanderfolgende schwarze bzw. weiße Pixel in den Eingabedaten vorkommen – beispielsweise bei einem Schwarz-Weiß-Scan einer Textseite, in dem sich große zusammenhängende weiße Bereiche mit kleineren schwarzen Bereichen abwechseln. Lauflängencodierung kommt daher unter anderem bei der Bildübertragung per Fax zum Einsatz.
Häufigkeitsbasierte Kompression
Bei der Lauflängencodierung werden direkt aufeinanderfolgende Zeichenwiederholungen ausgenutzt, um Daten zu komprimieren. Eine alternative Strategie besteht darin, Daten auf Grundlage der Häufigkeit der vorkommenden Zeichen zu komprimieren.1
Die Grundidee besteht darin, einzelne Zeichen nicht durch binäre Codewörter derselben Länge (z. B. 8 Bit pro Zeichen) zu codieren, sondern durch Codewörter unterschiedlicher Länge. Häufigere Zeichen werden dabei durch Codewörter kürzerer Länge repräsentiert und seltenere Zeichen durch längere Codewörter.
Der Morse-Code verwendet beispielsweise diese Strategie (die Buchstaben E und T werden mit nur einem Symbol codiert, J, Q, X und Z dagegen mit vier Symbolen). Beim Morsecode werden Pausen als Trennzeichen zwischen den Codewörtern verwendet, damit klar ist, wo ein Codewort endet und das nächste beginnt. Anderenfalls könnte eine Nachricht wie •••---••• nicht eindeutig als “SOS” decodiert werden, sondern könnte z. B. auch “EUGI” bedeuten.
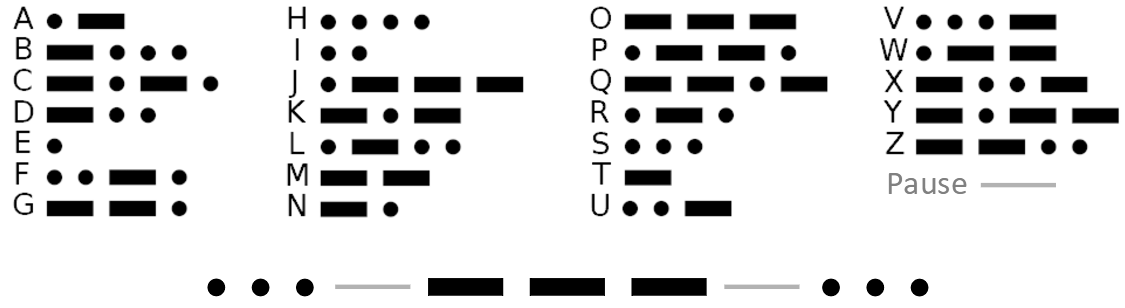
Wenn keine Trennzeichen zwischen Codewörten verwendet werden, muss sichergestellt sein, dass kein Codewort mit einem anderen Codewort beginnt. Eine solche Codierung heißt präfixfrei. Wenn beispielsweise ein Zeichen durch das binäre Codewort 01 repräsentiert wird, darf kein anderes Zeichen durch ein Codewort dargestellt werden, das mit der Bitfolge 01 beginnt, wie etwa 010 oder 0110. Anderenfalls ist die Decodierung nicht mehr eindeutig, wie das folgende Beispiel zeigt.
Beispiel: Angenommen, die zu codierenden Daten bestehen aus den Buchstaben A – F und wir ordnen diesen Zeichen die folgenden Codewörter zu:
A = 00, B = 01, C = 100, D = 11, E = 110, F = 111
Diese Codierung ist nicht präfixfrei, da die Codewörter für “E” und “F” jeweils mit dem Codewort für “D” beginnen.
Nun soll die Bitfolge 11100 decodiert werden. Hier ist nicht klar, ob das erste Zeichen ein “D” (Bitfolge 11) oder ein “F” (Bitfolge 111) ist, da es den codierten Daten nicht anzusehen ist, wie lang die einzelnen Codewörter sind. Die Bitfolge ließe sich gleichermaßen zu “DC” oder “FA” decodieren.
Die folgende Zuordnung von Codewörtern zu den Buchstaben ist dagegen präfixfrei:
A = 00, B = 01, C = 100, D = 101, E = 110, F = 111
Hier lässt sich die Bitfolge 11100 nur noch zu “FA” decodieren, die Decodierung ist also eindeutig.
Huffman-Codierung
Die Huffman-Codierung2 beschreibt ein Verfahren, um optimale binäre Codewörter basierend auf den Zeichenhäufigkeiten zu berechnen – also Codewörter, die zu einer möglichst kurzen Gesamtcodelänge führen. Das Verfahren garantiert dabei, dass die Codewörter präfixfrei, also eindeutig decodierbar sind.
Zur Codierung wird eine spezielle Datenstruktur, der sogenannte Huffman-Baum, aufgebaut, aus dem die Codewörter für die einzelnen Zeichen abgelesen werden können.

Codierung
Zuerst wird die Häufigkeit jedes Zeichens berechnet – es wird also gezählt, wie oft jedes Zeichen in den zu codierenden Daten vorkommt.
Anschließend wird der Huffman-Baum nach dem folgenden Algorithmus erstellt:
- Erstelle für jedes Zeichen einen einzelnen Knoten (also einen Baum mit nur einem Element), dessen Wert die Häufigkeit des Zeichens ist.
- Wiederhole, bis nur noch ein Baum übrig ist:
- Wähle die beiden Bäume, deren Wurzelknoten die geringsten Werte haben.
- Erstelle einen neuen Wurzelknoten, dessen Nachfolger die Wurzelknoten der beiden Bäume sind.
- Der Wert des neuen Wurzelknotens ist die Summe der Werte seiner beiden Nachfolger.
Beispiel: Die Textnachricht “OSTSEESPROTTENPOTT” soll mittels Huffman-Codierung komprimiert werden.

Als Erstes zählen wir, wie oft jedes Zeichen in der Nachricht vorkommt. Anschließend erstellen wir für jedes der sieben Zeichen einen Baum mit nur einem Knoten, dessen Wert die Häufigkeit des Zeichens ist.

Die Knoten für die Zeichen “N” und “R” haben die geringste Werte (jeweils 1), also werden sie mit einem neuen Wurzelknoten verbunden, dessen Wert 1 + 1 = 2 ist.

Nun haben der neue Baum und der Baum für das Zeichen “P” die geringsten Werte an der Wurzel stehen (jeweils 2). Ihre Wurzelknoten werden mit einem neuen Wurzelknoten dessen Wert 2 + 2 = 4 ist, zu einem neuen Baum verbunden.

Nun gibt es drei Knoten mit dem Wert 3. Es ist egal, welche der beiden wir in diesem Schritt verbinden. Hier werden die Knoten der Zeichen “O” und “S” gewählt und mit einem neuen Wurzelknoten mit dem Wert 3 + 3 = 6 verbunden.

Als Nächstes werden die Wurzelknoten der beiden Bäume mit den momentan geringsten Werten 3 und 4 verbunden. Der neue Baum hat den Wert 3 + 4 = 7 an der Wurzel stehen.

Nun werden die Wurzelknoten der beiden Bäume mit Werten 5 und 6 verbunden, der neue Wurzelknoten erhält den Wert 5 + 6 = 11.

Als Letztes werden die Wurzelknoten der letzten beiden Bäume mit Werten 7 und 11 verbunden, der neue Wurzelknoten erhält den Wert 7 + 11 = 18. Damit ist der Huffman-Baum fertiggestellt.
Auf diese Weise werden Schritt für Schritt jeweils zwei Bäume zusammengefügt, bis nur noch ein einziger Baum (der Huffman-Baum) übrig ist, dessen Wurzel als Wert die Gesamtanzahl aller Zeichen enthält. Jedes Blatt des Huffman-Baums repräsentiert ein Zeichen. Die Reihenfolge, in der die Bäume zusammengefügt werden, sorgt dafür, dass die Blätter seltenerer Zeichen weiter von den Wurzel entfernt sind, während die Blätter häufigerer Zeichen näher an der Wurzel liegen (gemessen in Kanten).
Aus dem Huffman-Baum lassen sich nun die Codewörter für jedes Zeichen ablesen. Dazu wird zuerst jede linke Kante von einem Knoten zu seinem Nachfolger mit 0 beschriftet und jede rechte Kante mit 1.

Um das Codewort für ein Zeichen zu ermitteln, wird dann folgendermaßen vorgegangen:
- Starte bei der Wurzel und gehe abwechselnd nach links oder rechts, bis das Blatt für das Zeichen erreicht ist.
- Die Bit-Werte auf den Kanten des Pfades von der Wurzel zum Blatt ergeben das Codewort für das Zeichen.
Beispiel:
Aus dem oben konstruierten Huffman-Baum erhalten wir das Codewort 01 für den Buchstaben “E”, da wir von der Wurzel aus erst nach links und anschließend nach rechts gehen müssen, um zum Blatt für das Zeichen “E” zu gelangen. Die Codewörter der einzelnen Buchstaben sind in der rechten Spalte der Tabelle eingetragen.
Damit erhalten wir die folgende Bitsequenz, wenn wir die gesamte Textnachricht Zeichen für Zeichen durch die Huffman-Codewörter ersetzen:
100101111010101101001000110011110100000011001111
Decodierung
Um eine Bitfolge zu decodieren, die mittels Huffman-Codierung entstanden ist, wird der Huffman-Baum benötigt, mit dem die Daten codiert wurden. Dabei dient die Bitfolge quasi als Anleitung, wie wir während der Decodierung durch den Huffman-Baum laufen. Immer wenn ein Blatt erreicht wird, wird das entsprechende Zeichen ausgegeben und bei der Wurzel neu gestartet.
Die Decodierung läuft also nach dem folgenden Algorithmus ab:
- Setze einen Zeiger auf den Wurzelknoten des Huffman-Baums.
- Wiederhole, bis die gesamte Bitfolge gelesen wurde:
- Lies das nächste Bit.
- Wenn das Bit
0ist, setze den Zeiger auf den linken Nachfolger des aktuellen Knotens, bei1auf den rechten. - Wenn ein Blatt erreicht wurde, gib das Zeichens des Blatts aus und setze den Zeiger auf den Wurzelknoten zurück.

Beispiel:
Mit dem oben konstruierten Huffman-Baum werden die ersten drei Bit 100 des Huffman-Codes zum Zeichen “O” decodiert: Beim Lesen der Bits wird von der Wurzel aus einmal nach rechts und anschließend zweimal nach links gegangen. Dabei wird das Blatt des Zeichens “O” erreicht, dieses Zeichen ausgegeben und der Zeiger auf den Wurzelknoten zurückgesetzt.
Speicheraufwand
In dem oben gezeigten Beispiel ergibt sich eine Codelänge von 48 Bit. Zum Vergleich: Wenn die Textdaten unkomprimiert im üblichen (erweiterten) ASCII-Format gespeichert werden, werden 8 Bit pro Zeichen benötigt – da die Nachricht 18 Zeichen enthält also ingesamt 8·18 = 144 Bit. Damit beträgt der Kompressionsfaktor der Huffman-Codierung hier 48 / 144 = 33.3%, die Kompressionsrate liegt bei 3 : 1.
Wenn wir stattdessen jedes Zeichen mit einem Codewort der gleichen Länge codieren würden, würden wir 3 Bit pro Zeichen benötigen, um die 7 verschiedenen Buchstaben im Text zu unterscheiden – insgesamt also 3·18 = 54 Bit. Der Kompressionsfaktor für dieses Verfahren beträgt hier 54 / 144 = 37.5%, schneidet also schlechter ab als die Huffman-Codierung.
Bei dieser Berechnung wird allerdings ignoriert, dass zusätzlicher Speicherbedarf für den Huffman-Baum nötig ist: Da der Huffman-Baum zur Decodierung bekannt sein muss, muss er zusammen mit den komprimierten Daten gespeichert werden. Wenn die Eingabedaten groß genug sind, wiegt die Speicherersparnis, die sich durch das Komprimieren der Daten ergibt, den zusätzlichen Speicherbedarf für den Huffman-Baum aber wieder auf.
Wörterbuchbasierte Kompression
Bestimmte Zeichenfolgen kommen in der Regel mit unterschiedlicher Häufigkeit in Daten vor. So enthalten deutschsprachige Texte beispielsweise sehr häufig Zeichenfolgen wie “ein”, “der”, “die” oder “sch”. Solche häufig vorkommenden Zeichenfolgen können ebenfalls ausgenutzt werden, um Daten zu komprimieren. Dazu werden Tabellen verwendet, die Zeichenfolgen auf binäre Codewörter abbilden und als Wörterbücher bezeichnet werden.
Bei wörterbuchbasierten Kompressionsverfahren besteht also die Grundidee darin, dass nicht nur einzelne Zeichen codiert werden, sondern auch häufiger vorkommende Zeichenfolgen durch einzelne Codewörter dargestellt werden. Dazu muss zunächst ermittelt werden, welche Zeichenfolgen besonders oft in den zu codierenden Daten vorkommen. In einem Wörterbuch wird für jedes Zeichen und jede Zeichenfolge ein Codewort festgehalten, durch den diese in der Ausgabe dargestellt werden. Das Codewort ist dabei in Regel einfach die Nummer des Eintrags im Wörterbuch (binär codiert).

Um die Daten zu decodieren, muss das Wörterbuch bekannt sein. Wenn es möglich ist, das Wörterbuch während der Decodierung mit derselben Strategie zu rekonstruieren, mit der es während der Codierung aufgebaut wurde, kann aber darauf verzichtet werden, das Wörterbuch mit den komprimierten Daten zusammen zu speichern.
LZW-Algorithmus
Ein sehr bekanntes Kompressionsverfahren, das auf dieser Idee basiert, ist der Lempel-Ziv-Welch-Algorithmus (kurz LZW-Algorithmus).3
Beim LZW-Algorithmus wird während der Codierung der Eingabedaten ein Wörterbuch aufgebaut, in das Schritt für Schritt Zeichenfolgen steigender Länge, die bisher aus den Eingabedaten gelesen wurden, hinzugefügt werden. Das Codewort für eine Zeichenfolge im Wörterbuch ist dabei die Nummer des Eintrags, also die Position des Eintrags im Wörterbuch (binär codiert als Bitfolge) – der LZW-Algorithmus liefert als Ausgabe also eine Sequenz von Nummern von Wörterbucheinträgen. Der Einfachheit halber werden diese Nummern im Folgenden immer als Dezimalzahlen dargestellt.
Codierung
Zu Beginn enthält das Wörterbuch je einen Eintrag für alle Zeichen, die in der zu codierenden Nachricht vorkommen. Die Einträge des Wörterbuchs werden beginnend mit 0 durchnummeriert.
Der Algorithmus zur Codierung ist folgendermaßen beschrieben:
- Starte am Anfang der Eingabe.
- Wiederhole, bis die Eingabe vollständig verarbeitet wurde:
- Lies zeichenweise eine Zeichenfolge s aus der Eingabe, bis die Zeichenfolge s + das folgende Zeichen nicht mehr im Wörterbuch vorkommt.
- Schreibe die Eintragsnummer von s in die Ausgabe.
- Füge als neuen Wörterbucheintrag s + das folgende Zeichen hinzu.
- Verarbeite die Eingabe nun ab dem folgenden Zeichen weiter.
Beispiel: Der schrittweise Ablauf des Algorithmus soll anhand der Codierung der Textnachricht “ANANASBANANA” veranschaulicht und erläutert werden:

Das initiale Wörterbuch enthält vier Einträge für die Buchstaben “A”, “B”, “N” und “S” mit den Nummern 0 bis 3.

Das Zeichen “A” wird gelesen (längere Zeichenfolgen enthält das Wörterbuch zu diesem Zeitpunkt noch nicht).
Die Eintragsnummer des Zeichens “A” wird in die Ausgabe geschrieben, also 0.
Als neuer Eintrag mit der Nummer 4 wird die Zeichenfolge “AN” zum Wörterbuch hinzugefügt.

Das Zeichen “N” wird gelesen (das Wörterbuch enthält die nächstlängere Zeichenfolge “NA” bisher nicht).
Die Eintragsnummer des Zeichens “N” wird in die Ausgabe geschrieben, also 2.
Als neuer Eintrag Nummer 5 wird “NA” hinzugefügt.

Die Zeichenfolge “AN” wird gelesen, die im 1. Schritt zum Wörterbuch hinzugefügt wurde.
Die Eintragsnummer 4 der Zeichenfolge “AN” wird ausgegeben.
Als neuer Eintrag Nummer 6 wird “ANA” hinzugefügt.

Das Zeichen “A” wird gelesen (das Wörterbuch enthält die nächstlängere Zeichenfolge “AS” bisher nicht).
Die Eintragsnummer 0 des Zeichens “A” wird in die Ausgabe geschrieben.
Als neuer Eintrag Nummer 7 wird “AS” hinzugefügt.

Nach diesem Schema wird fortgefahren, solange noch Zeichen aus der Eingabe abzuarbeiten sind.

Nach diesem Schema wird fortgefahren, solange noch Zeichen aus der Eingabe abzuarbeiten sind.

Nach diesem Schema wird fortgefahren, solange noch Zeichen aus der Eingabe abzuarbeiten sind.

Im letzten Schritt wird kein neuer Eintrag zum Wörterbuch hinzugefügt.
Als Ausgabe erhalten wir hier die folgende Sequenz von Eintragsnummern:
0, 2, 4, 0, 3, 1, 6, 5
Verwenden Sie den folgenden Simulator, um diesen Algorithmus selbst Schritt für Schritt bis zum Ende nachzuvollziehen.
Interaktiver LZW-Codierer
Tool:
In dieser interaktiven Anzeige können Sie die LZW-Codierung einer Textnachricht Schritt für Schritt simulieren und dabei den Aufbau des Wörterbuchs nachvollziehen. Die letzte Spalte “Codewort” stellt hier die Nummer des Wörterbucheintrags als Binärzahl dar, die für die Ausgabe im Binärformat verwendet wird.
Mit der Schaltfläche “Nächster Schritt” wird die nächste Zeichenfolge aus der Eingabe gelesen und codiert. Wählen Sie “Codierung zurücksetzen”, um eine neue Textnachricht einzugeben.
ANANASBANANA
| Nummer | Zeichenfolge | Codewort |
|---|
Decodierung
Für die Decodierung muss nicht das vollständige Wörterbuch bekannt sein, es wird nur der Initialzustand benötigt, also die Einträge für die einzelnen Zeichen, die in der codierten Nachricht vorkommen. Alle weiteren Einträge werden während der Decodierung Schritt für Schritt rekonstruiert.
Die Decodierung startet also mit demselben initialen Wörterbuch wie die Codierung. Als Eingabe dient hier die Sequenz der Eintragsnummern, die bei der Codierung erzeugt wurde.
- Wiederhole, bis die Eingabe vollständig verarbeitet wurde:
- Lies die nächste Nummer N aus der Eingabe.
- Schreibe die Zeichenfolge, die im N-ten Wörterbucheintrag steht, in die Ausgabe.
- Füge als neuen Wörterbucheintrag die folgende Zeichenfolge hinzu: die im letzten Schritt ausgegebene Zeichenfolge + das erste Zeichen der im aktuellen Schritt ausgegebenen Zeichenfolge (im 1. Schritt der Decodierung wird diese Anweisung übersprungen)
Die letzte Anweisung wirkt auf den ersten Blick etwas seltsam: Hier wird das Hinzufügen der neuen Wörterbucheinträge während der Codierung nachvollzogen, allerdings mit einem Schritt Verzögerung.4
Hierdurch ergibt sich ein Fallstrick: Bei der Codierung kann es passieren, dass eine Zeichenfolge zum Wörterbuch hinzugefügt wird und gleich im nächsten Schritt für die Ausgabe verwendet wird. Überprüfen Sie als Beispiel die Codierung des Textes “ABABABA” im interaktiven LZW-Codierer:
- Im 3. Schritt wird die Nummer des Eintrags “AB” ausgegeben und als neuer Eintrag Nummer 4 die Zeichenfolge “ABA” hinzugefügt.
- Im 4. Schritt wird die Nummer des Eintrags “ABA” ausgegeben, der im vorigen Schritt zum Wörterbuch hinzugefügt wurde.
Bei der Decodierung tritt nun 4. Schritt also das Problem auf, dass die Nummer 4 decodiert werden soll, der 4. Eintrag aber erst in diesem Decodierungsschritt zum Wörterbuch hinzugefügt wird. Wie lautet also die Zeichenfolge mit der Nummer 4?


Dieses Problem lässt sich durch die folgenden Überlegungen lösen:
- Laut Decodierungsalgorithmus wird in diesem Schritt als neuer Wörterbucheintrag (Nummer 4) die im letzten Schritt ausgegebene Zeichenfolge + das erste Zeichen der im aktuellen Schritt auszugebenden Zeichenfolge eingetragen.
- Im letzten Schritt wurde “AB” ausgegeben, also lautet der neue Wörterbucheintrag “AB?”, wobei das Zeichen ? noch unbekannt ist.
- In diesem Schritt wird also “AB?” ausgegeben, die im aktuellen Schritt ausgegebene Zeichenfolge beginnt also mit “A”.
- Also ist “A” das unbekannte Zeichen ?, die Zeichenfolge, die in diesem Schritt ausgegeben und zum Wörterbuch hinzugefügt wird, lautet demnach “ABA”.
Generell wird in dieser Situation also immer die im letzten Schritt ausgegebene Zeichenfolge + deren erstes Zeichen zum Wörterbuch hinzugefügt und ausgegeben.
Binäre Codewörter
Im einfachsten Fall werden die Nummern, die der LZW-Algorithmus als Ausgabe produziert, als binär codierte Ganzzahlen mit fester Bitlänge (z. B. 12 Bit pro Nummer) repräsentiert. Das Wörterbuch kann dann aber nur eine begrenzte Anzahl von Einträgen aufnehmen (bei 12 Bit/Nummer insgesamt 212= 4096 Einträge). Wenn das Wörterbuch während der Codierung/Decodierung seine maximale Größe erreicht, können keine weiteren Einträge mehr hinzugefügt werden und im weiteren Verlauf nur die bereits vorhandenen Einträge verwendet werden.
Dieses Verfahren ist außerdem unnötig speicheraufwendig: Angenommen, das Wörterbuch enthält zu Beginn 10 Einträge. Dann reichen 4 Bit, um die Nummern der Einträge zu Beginn der Codierung darzustellen. Erst wenn das Wörterbuch nach 6 Schritte 16 Einträge umfasst, sind ab dann 5 Bit nötig, um die Nummern in der Ausgabe darzustellen. Verdoppelt sich die Anzahl der Einträge nach weiteren 16 Schritten auf 32, ist ein weiteres Bit nötig.
Diese Strategie wird beim LZW-Algorithmus verwendet: Es werden immer nur soviele Bit zur Codierung der Nummern in der Ausgabe verwendet, wie nötig sind, um die Nummern aller momentan im Wörterbuch vorhandenen Einträge darzustellen. Sobald die Wörterbuchlänge die nächste Zweierpotenz erreicht, wird 1 Bit zur Binärdarstellung der Nummern in der Ausgabe dazugenommen.
Bei der Decodierung wird die gleiche Strategie verwendet, um zu bestimmen, wie viele Bit jeweils für das nächste Codewort aus der Eingabe gelesen werden. Kurz zusammengefasst gilt in jedem Schritt: Wenn das Wörterbuch N Einträge enthält, werden ⌈log2(N)⌉ Bit für jedes Codewort gelesen/ausgegeben.
Im interaktiven LZW-Codierer können Sie über die Option ☑ binäre Ausgabe? nachvollziehen, wie die Codewörter im Binärformat mit wachsender Länge ausgegeben werden (die Leerzeichen dienen hier nur dazu, dass Sie die einzelnen Codewörter in der Ausgabe einfacher auseinanderhalten können).
Dateiformate
Die Kompressionsverfahren, die in dieser Lektion exemplarisch vorgestellt werden, finden (zum Teil in modifizierter Form) in vielen gängigen Dateiformaten Verwendung. Da die Verfahren unterschiedliche Stärken haben, werden sie meistens nicht einzeln, sondern in Kombination angewendet. Sehr verbreitet ist beispielsweise der “Deflate”-Algorithmus: Dabei wird neben der Huffman-Codierung eine spezielle Variante des Lempel-Ziv-Algorithmus verwendet, der dem LZW-Algorithmus ähnlich ist.
Abschließend finden Sie hier einen kurzen Überblick über bekannte Dateiformate für Rastergrafiken und Archive und die darin verwendeten Kompressionsverfahren.
| Dateiformate für Rastergrafiken | |
|---|---|
| Das JPEG-Format verwendet verlustbehaftete Kompression, wobei sich über einen Parameter das Verhältnis zwischen Kompressionsfaktor und Bildqualität steuern lässt. Je höher der Kompressionsfaktor, desto ungenauer lässt sich das Originalbild rekonstruieren. Der JPEG-Algorithmus verwendet dabei Lauflängencodierung und Huffman-Codierung als Zwischenschritte. | |
| Das PNG-Format verwendet unter anderem eine Kombination von Lempel-Ziv-Algorithmus und Huffman-Codierung (“Deflate”-Algorithmus). Die Codierung ist also verlustfrei. | |
| Das GIF-Format verwendet dagegen nur den LZW-Algorithmus und erreicht dadurch eine geringere Kompression als PNG. | |
| Windows Bitmap (BMP) verwendet nur Lauflängencodierung und erreicht dadurch nur eine schwache Kompression. | |
| Das TIFF-Format unterstützt verschiedene Kompressionsverfahren, unter anderem LZW und Lauflängencodierung, aber auch verlustbehaftete Kompression. |
| Dateiformate für Archive | |
|---|---|
| Das ZIP-Dateiformat (von engl. zipper = Reißverschluss) ist ein Format für verlustfrei komprimierte Dateien, das zur Archivierung oder zum Versand von Dateien verwendet wird. Die Dateien werden dabei einzeln komprimiert und in einer Archiv-Datei zusammengefasst. ZIP unterstützt verschiedene verlustfreie Kompressionsverfahren. Standardmäßig wird der “Deflate”-Algorithmus verwendet (Kombination von Lempel-Ziv-Algorithmus und Huffman-Codierung). | |
| Das RAR-Dateiformat5 ist ein Archiv-Dateiformat, das stärkere Kompression als ZIP erreicht. Das Dateiformat ist allerdings nicht frei und der Kompressionsalgorithmus nicht offen zugänglich, weswegen RAR inzwischen weniger stark verbreitet ist. |
Kompressionsverfahren, die den einzelnen Zeichen der zu codierenden Daten basierend auf ihrer Häufigkeit unterschiedlich lange Bitfolgen zuordnen, werden unter der Bezeichnung Entropiecodierung zusammengefasst. Die Entropie ist in der Informationstheorie anschaulich ausgedrückt ein Maß dafür, wie gleichmäßig die Zeichen in den zugrundeliegenden Daten verteilt sind. ↩︎
Die Huffman-Codierung ist nach ihrem Entwickler David A. Huffman benannt, der das Verfahren 1952 publizierte. ↩︎
Der LZW-Algorithmus ist nach seinen ursprünglichen Entwicklern Abraham Lempel und Jacob Ziv, sowie nach Terry A. Welch benannt. Lempel und Ziv veröffentlichten 1977 die erste Version des Verfahrens unter dem Namen LZ77, sowie 1978 dessen Nachfolger LZ78, der nach Detailverbesserungen durch Welch 1984 unter dem Namen LZW publiziert wurde. ↩︎
Zur Erklärung: Bei der Codierung wird in jedem Schritt die aktuell verarbeitete Zeichenfolge + das erste Zeichen der im nächsten Schritt verarbeiteten Zeichenfolge zum Wörterbuch hinzugefügt. Bei der Decodierung wird analog dazu in jedem Schritt die im vorigen Schritt ausgegebene Zeichenfolge + das erste Zeichen der aktuell ausgegebenen Zeichenfolge zum Wörterbuch hinzugefügt. ↩︎
Das RAR-Dateiformat (“Roshal ARchive”) ist nach seinem Entwickler Jewgeni Lasarewitsch Roschal benannt. ↩︎